|
|
| Line 1: |
Line 1: |
| <div class="title">OX Drive API</div> | | <div class="title">Running a cluster</div> |
|
| |
|
| __TOC__ | | __TOC__ |
|
| |
|
| = Introduction = | | = Concepts = |
|
| |
|
| The module <code>drive</code> is used to synchronize files and folders between server and client, using a server-centric approach to allow an easy implementation on the client-side.
| | For inter-OX-communication over the network, multiple Open-Xchange servers can form a cluster. This brings different advantages regarding distribution and caching of volatile data, load balancing, scalability, fail-safety and robustness. Additionally, it provides the infrastructure for upcoming features of the Open-Xchange server. |
| | The clustering capabilities of the Open-Xchange server are mainly built up on [http://hazelcast.com Hazelcast], an open source clustering and highly scalable data distribution platform for Java. The following article provides an overview about the current featureset and configuration options. |
|
| |
|
| The synchronization is based on checksums for files and folders, differences between the server- and client-side are determined using a three-way comparison of server, client and previously acknowledged file- and directory-versions. The synchronization logic is performed by the server, who instructs the client with a set of actions that should be executed in order to come to a synchronized state.
| | = Requirements on HTTP routing = |
|
| |
|
| Therefore, the client takes a snapshot of it's local files and directories, calculates their checksums, and sends them as a list to the server, along with a list of previously acknowledged checksums. The server takes a similar snapshot of the files and directories on the underlying file storages and evaluates which further actions are necessary for synchronization. After executing the server-side actions, the client receives a list of actions that should be executed on the client-side. These steps are repeated until the server-state matches the client-state.
| | An OX cluster is always part of a larger picture. Usually there is front level loadbalancer as central HTTPS entry point to the platform. This loadbalancer optionally performs HTTPS termination and forwards HTTP(S) requests to webservers (the usual and only supported choice as of now is Apache). These webservers are performing HTTPS termination (if this is not happening on the loadbalancer) and serve static content, and (which is what is relevant for our discussion here) they forward dynamic requests to the OX backends. |
|
| |
|
| Key concept is that the synchronization works stateless, i.e. it can be interrupted and restarted at any time, following the eventual consistency model.
| | A central requirement for the interaction of these components (loadbalancer, webservers, OX nodes) is that we have session stability based on the JSESSIONID cookie / jsessionid path component suffix. This means that our application sets a cookie named JSESSIONID which has a value like <large decimal number>.<route identifier>, e.g. "5661584529655240315.OX1". The route identifier here ("OX1" in this example) is taken by the OX node from a configuration setting from a config file and is specific to one OX node. HTTP routing must happen such that HTTP requests with a cookie with such a suffix always end up the corresponding OX node. There are furthermore specific cirumstances when passing this information via cookie is not possible. Then the JSESSIONID is transferred in a path component as "jsessionid=..." in the HTTP request. The routing mechanism needs to take that into account also. |
|
| |
|
| Entry point for the synchronization is the [[#Synchronize_folders|<code>syncfolders</code>]] request, where the directories are compared, and further actions are determined by the server, amongst others actions to synchronize the files in a specific directory using the [[#Synchronize_files_in_a_folder|<code>syncfiles</code>]] request. After executing the actions, the client should send another <code>syncfolders</code> request to the server and execute the returned actions (if present), or finish the synchronization if there are no more actions to execute. In pseudo-code, the synchronization routine could be implemented as follows:
| | There are mainly two options to implement this. If the Apache processes are running co-located on the same machines running the OX groupware processes, it is often desired to have the front level loadbalancer perform HTTP routing to the correct machines. If dedicated Apache nodes are employed, is is usually sufficient to have the front-level loadbalancer do HTTP routing to the Apache nodes in a round-robin fashion and perform routing to the correct OX nodes in the Apache nodes. |
|
| |
|
| WHILE TRUE
| | We provide sample configuration files to configure Apache (with mod_proxy_http) to perform HTTP routing correctly in our guides on OXpedia, e.g. [[AppSuite:Main_Page_AppSuite#quickinstall]]. Central elements are the directives "ProxySet stickysession=JSESSIONID|jsessionid scolonpathdelim=On" in conjunction with the "route=OX1" parameters to the BalancerMember lines in the Proxy definition. This is valid for Apache 2.2 as of Sep-2014. |
| {
| |
| response = SYNCFOLDERS()
| |
| IF 0 == response.actions.length
| |
| BREAK
| |
| ELSE
| |
| EXECUTE(response.actions)
| |
| }
| |
|
| |
|
| Basically, it's up to the client how often such a synchronization cycle is initiated. For example, he could start a new synchronization cycle after a fixed interval, if he recognizes that the client directories have changed, or if he is informed that something has changed on the server by an event. It's also up to the client to interrupt the synchronization cycle at any time during execution of the actions and continue later on, however, it's recommended to start a new synchronization cycle each time to avoid possibly outdated actions.
| | How to configure a front level loadbalancer to perform HTTP equivalent HTTP routing is dependent on the specific loadbalancer implementation. If Apache is used as front level loadbalancer, the same configuration as discussed in the previous section can be employed. As of time of writing this text (Sep 2014), the alternative choices are thin. F5 BigIP is reported to be able to implement "jsessionid based persistence using iRules". nginx has the functionality in their commercial "nginx plus" product. (Both of these options have not been tested by OX.) Other loadbalancers with this functionality are not known to us. |
|
| |
|
| = API =
| | If the front level loadbalancer is not capable of performing correct HTTP routing, is is required to configure correct HTTP routing on Apache level, even if Apache runs co-located on the OX nodes and thus cross-routing happens. |
|
| |
|
| As part of the [[HTTP_API|HTTP API]], the basic conventions for exchanging messages that described there are also valid for this case, especially the [[HTTP_API#Low_level_protocol|low level protocol]] and [[HTTP_API#Error_handling|error handling]]. Each request against the Drive API assumes a valid server session that is uniquely identified by the session id and the corresponding cookies and are sent with each request. A new session can be created via the [[HTTP_API#Module_.22login.22|login module]].
| | There are several reasons why we require session stability in exactly this way. We require session stabilty for horizontal scale-out; while we support transparent resuming / migration of user sessions in the OX cluster without need for users to re-authenticate, sessions wandering around randomly will consume a fixed amount resources corresponding to a running session on each OX node in the cluster, while a session sticky to one OX node will consume this fixed amount of resources only on one OX node. Furthermore there are mechanisms in OX like TokenLogin which work only of all requests beloning to one sequence get routed to the same OX node even if they stem from different machines with different IPs. Only the JSESSIONID (which in this case is transferred as jsessionid path component, as cookies do not work during a 302 redirect, which is part of this sequence) carries the required information where the request must be routed to. |
|
| |
|
| The root folder plays another important role for the message exchange. The root folder has a unique identifier. It is the parent server folder for the synchronization. All path details for directories and files are relative to this folder. This folder's id is sent with each request. To select the root folder during initial client configuration, the client may get a list of synchronizable folders with the [[#Get_synchronizable_Folders|<code>subfolders</code>]] action.
| | Usual "routing based on cookie hash" is not sufficient here since it disregards the information which machine originally issued the cookie. It only ensures that the session will be sticky to any target, which statistically will not be the same machine that issued the cookie. OX will then set a new JSESSIONID cookie, assuming the session had been migrated. The loadbalancer will then route the session to a different target, as the hash of the cookie will differ. This procedure then happens iteratively until by chance the routing based on cookie hash will route the session to the correct target. By then, a lot of resources will have been wasted, by creating full (short-term) sessions on all OX nodes. Furthermore, processes like TokenLogin will not work this way. |
|
| |
|
| Subsequently all transferred objects and all possible actions are listed.
| | = Configuration = |
|
| |
|
| == File Version ==
| | All settings regarding cluster setup are located in the configuration file ''hazelcast.properties''. The former used additional files ''cluster.properties'', ''mdns.properties'' and ''static-cluster-discovery.properties'' are no longer needed. The following gives an overview about the most important settings - please refer to the inline documentation of the configuration file for more advanced options. |
|
| |
|
| A file in a directory is uniquely identified by its filename and the checksum of its content.
| | Note: The configuration guide targets v7.4.0 of the OX server (and above). For older versions, please consult the history of this page. |
|
| |
|
| {| id="FileVersion" cellspacing="0" border="1"
| | == General == |
| |+ align="bottom" | File Version
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | name || String || The name of the file, including its extension, e.g. <code>test.doc</code>.
| |
| |-
| |
| | checksum || String || The MD5 hash of the file, expressed as a lowercase hexadecimal number string, 32 characters long, e.g. <code>f8cacac95379527cd4fa15f0cb782a09</code>.
| |
| |}
| |
|
| |
|
| == Directory Version ==
| | To restrict access to the cluster and to separate the cluster from others in the local network, a name and password needs to be defined. Only backend nodes having the same values for those properties are able to join and form a cluster. |
|
| |
|
| A directory is uniquely identified by its full path, relative to the root folder, and the checksum of its content.
| | # Configures the name of the cluster. Only nodes using the same group name |
| | | # will join each other and form the cluster. Required if |
| {| id="DirectoryVersion" cellspacing="0" border="1"
| | # "com.openexchange.hazelcast.network.join" is not "empty" (see below). |
| |+ align="bottom" | Directory Version
| | com.openexchange.hazelcast.group.name= |
| ! Name !! Type !! Value
| |
| |-
| |
| | path || String || The path of the directory, including the directory's name, relative to the root folder, e.g. <code>/sub/test/letters</code>.
| |
| |-
| |
| | checksum || String || The MD5 hash of the directory, expressed as a lowercase hexadecimal number string, 32 characters long, e.g. <code>f8cacac95379527cd4fa15f0cb782a09</code>.
| |
| |}
| |
| | |
| Note: the checksum of a directory is calculated based on its contents in the following algorithm:
| |
| | |
| * Build a list containing each file in the directory (not including subfolders or files in subfolders)
| |
| * Ensure a lexicographically order in the following way:
| |
| ** Normalize the filename using the <code>NFC</code> normalization form (canonical decomposition, followed by canonical composition) - see http://www.unicode.org/reports/tr15/tr15-23.html for details
| |
| ** Encode the filename to an array of UTF-8 unsigned bytes (array of codepoints)
| |
| ** Compare the filename (encoded as byte array "fn1") to another one "fn2" using the following comparator algorithm:
| |
| | |
| min_length = MIN(LENGTH(fn1), LENGTH(fn2))
| |
| FOR i = 0; i < min_length; i++
| |
| {
| |
| result = fn1[i] - fn2[i]
| |
| IF 0 != result RETURN result
| |
| }
| |
| RETURN LENGTH(fn1) - LENGTH(fn2)
| |
| | |
| * Calculate the aggregated MD5 checksum for the directory based on each file in the ordered list:
| |
| ** Append the file's NFC-normalized (see above) name, encoded as UTF-8 bytes
| |
| ** Append the file's MD5 checksum string, encoded as UTF-8 bytes
| |
| | |
| == Actions ==
| |
| | |
| All actions are encoded in the following format. Depending on the action type, not all properties may be present.
| |
| | |
| {| id="Actions" cellspacing="0" border="1"
| |
| |+ align="bottom" | Actions
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | action || String || The type of action to execute, currently one of <code>acknowledge</code>, <code>edit</code>, <code>download</code>, <code>upload</code>, <code>remove</code>, <code>sync</code>, <code>error</code>.
| |
| |-
| |
| | version || Object || The (original) file- or directory-version referenced by the action.
| |
| |-
| |
| | newVersion || Object || The (new) file- or directory-version referenced by the action.
| |
| |-
| |
| | path || String || The path to the synchronized folder, relative to the root folder.
| |
| |-
| |
| | offset || Number || The requested start offset in bytes for file uploads.
| |
| |-
| |
| | totalLength || Number || The total length in bytes for file downloads.
| |
| |-
| |
| | contentType || String || The file's content type for downloads.
| |
| |-
| |
| | created || Timestamp || The file's creation time (always UTC, not translated into user time).
| |
| |-
| |
| | modified || Timestamp || The file's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | error || Object || The error object in case of synchronization errors.
| |
| |-
| |
| | quarantine || Boolean || The flag to indicate whether versions need to be excluded from synchronization.
| |
| |-
| |
| | reset || Boolean || The flag to indicate whether locally stored checksums should be invalidated.
| |
| |-
| |
| | stop || Boolean || The flag to signal that the client should stop the current synchronizsation cycle.
| |
| |-
| |
| | acknowledge || Boolean || The flag to signal if the client should not update it's stored checksums when performing an <code>EDIT</code> action.
| |
| |-
| |
| | thumbnailLink || String || A direct link to a small thumbnail image of the file if available (deprecated, available until API version 2).
| |
| |-
| |
| | previewLink || String || A direct link to a medium-sized preview image of the file if available (deprecated, available until API version 2).
| |
| |-
| |
| | directLink || String || A direct link to the detail view of the file in the web interface (deprecated, available until API version 2).
| |
| |-
| |
| | directLinkFragments || String || The fragments part of the direct link (deprecated, available until API version 2).
| |
| |}
| |
| | |
| The following list gives an overview about the used action types:
| |
| | |
| === <code>acknowledge</code> ===
| |
| Acknowledges the successful synchronization of a file- or directory version, i.e., the client should treat the version as synchronized by updating the corresponding entry in its metadata store and including this updated information in all following <code>originalVersions</code> arrays of the <code>syncfiles</code> / <code>syncfolders</code> actions. Depending on the <code>version</code> and <code>newVersion</code> parameters of the action, the following acknowledge operations should be executed (exemplarily for directory versions, file versions are acknowledged in the same way):
| |
| | |
| * Example 1: Acknowledge a first time synchronized directory <br /> The server sends an <code>acknowledge</code> action where the newly synchronized directory version is encoded in the <code>newVersion</code> parameter. The client should store the version in his local checksum store and send this version in the <code>originalVersions</code> array in upcoming <code>syncfolders</code> requests.
| |
| {
| |
| "action" : "acknowledge",
| |
| "newVersion" : {
| |
| "path" : "/",
| |
| "checksum" : "d41d8cd98f00b204e9800998ecf8427e"
| |
| }
| |
| }
| |
| | |
| * Example 2: Acknowledge a synchronized directory after updates <br /> The server sends an <code>acknowledge</code> action where the previous directory version is encoded in the <code>version</code>, and the newly synchronized directory in the <code>newVersion</code> parameter. The client should replace any previously stored entries of the directory version in his local checksum store with the updated version, and send this version in the <code>originalVersions</code> array in upcoming <code>syncfolders</code> requests.
| |
| {
| |
| "action" : "acknowledge",
| |
| "newVersion" : {
| |
| "path" : "/",
| |
| "checksum" : "7bb1f1a550e9b9ab4be8a12246f9d5fb"
| |
| },
| |
| "version" : {
| |
| "path" : "/",
| |
| "checksum" : "d41d8cd98f00b204e9800998ecf8427e"
| |
| }
| |
| }
| |
| | |
| * Example 3: Acknowledge the deletion of a previously synchronized directory <br /> The server sends an <code>acknowledge</code> where the <code>newVersion</code> parameter is set to <code>null</code> to acknowledge the deletion of the previously synchronized directory version as found in the <code>version</code> parameter. The client should remove any stored entries for this directory from his local checksum store, and no longer send this version in the <code>originalVersions</code> array in upcoming <code>syncfolders</code> requests. <br /> Note that an acknowledged deletion of a directory implicitly acknowledges the deletion of all contained files and subfolders, too, so the client should also remove those <code>originalVersion</code>s from his local checksum store.
| |
| {
| |
| "action" : "acknowledge",
| |
| "version" : {
| |
| "path" : "/test",
| |
| "checksum" : "3525d6f28eb8cb30eb61ab7932367c35"
| |
| }
| |
| }
| |
| | |
| === <code>edit</code> ===
| |
| Instructs the client to edit a file- or directory version. This is used for move/rename operations. The <code>version</code> parameter is set to the version as sent in the <code>clientVersions</code> array of the preceding <code>syncfiles</code>/</code>syncfolders</code> action. The <code>newVersion</code> contains the new name/path the client should use. Unless the optional boolean parameter <code>acknowledge</code> is set to <code>false</code> an <code>edit</code> action implies that the client updates its known versions store accordingly, i.e. removes the previous entry for <code>version</code> and adds a new entry for <code>newVersion</code>.
| |
| When editing a directory version, the client should implicitly take care to create any not exisiting subdirectories in the <code>path</code> of the <code>newVersion</code> parameter.
| |
| A concurrent client-side modification of the file/directory version can be detected by the client by comparing the current checksum against the one in the passed <code>newVersion</code> parameter.
| |
| | |
| * Example 1: Rename a file <br /> The server sends an <code>edit</code> action where the source file is encoded in the <code>version</code>, and the target file in the <code>newVersion</code> parameter. The client should rename the file identified by the <code>version</code> parameter to the name found in the <code>newVersion</code> parameter. Doing so, the stored checksum entry for the file in <code>version</code> should be updated, too, to reflect the changes.
| |
| { | |
| "path" : "/",
| |
| "action" : "edit",
| |
| "newVersion" : {
| |
| "name" : "test_1.txt",
| |
| "checksum" : "03395a94b57eef069d248d90a9410650"
| |
| },
| |
| "version" : {
| |
| "name" : "test.txt",
| |
| "checksum" : "03395a94b57eef069d248d90a9410650"
| |
| }
| |
| }
| |
| | |
| * Example 2: Move a directory <br /> The server sends an <code>edit</code> action where the source directory is encoded in the <code>version</code>, and the target directory in the <code>newVersion</code> parameter. The client should move the directory identified by the <code>version</code> parameter to the path found in the <code>newVersion</code> parameter. Doing so, the stored checksum entry for the directory in <code>version</code> should be updated, too, to reflect the changes.
| |
| {
| |
| "action" : "edit",
| |
| "newVersion" : {
| |
| "path" : "/test2",
| |
| "checksum" : "3addd6de801f4a8650c5e089769bdb62"
| |
| },
| |
| "version" : {
| |
| "path" : "/test1/test2",
| |
| "checksum" : "3addd6de801f4a8650c5e089769bdb62"
| |
| }
| |
| }
| |
| | |
| * Example 3: Rename a conflicting file <br /> The server sends an <code>edit</code> action where the original client file is encoded in the <code>version</code>, and the target filename in the <code>newVersion</code> parameter. The client should rename the file identified by the <code>version</code> parameter to the new filename found in the <code>newVersion</code> parameter. If the <code>acknowledge</code> parameter is set to <code>true</code> or is not set, the stored checksum entry for the file in <code>version</code> should be updated, too, to reflect the changes, otherwise, as in this example, no changes should be done to the stored checksums.
| |
| {
| |
| "action" : "edit",
| |
| "version" : {
| |
| "checksum" : "fade32203220752f1fa0e168889cf289",
| |
| "name" : "test.txt"
| |
| },
| |
| "newVersion" : {
| |
| "checksum" : "fade32203220752f1fa0e168889cf289",
| |
| "name" : "test (TestDrive).txt"
| |
| },
| |
| "acknowledge" : false,
| |
| "path" : "/"
| |
| }
| |
| | |
| === <code>download</code> ===
| |
| Contains information about a file version the client should download. For updates of existing files, the previous client version is supplied in the <code>version</code> parameter. For new files, the <code>version</code> parameter is omitted. The <code>newVersion</code> holds the target file version, i.e. filename and checksum, and should be used for the following <code>download</code> request. The <code>totalLength</code> parameter is set to the file size in bytes, allowing the client to recognize when a download is finished. Given the supplied checksum, the client may decide on its own if the target file needs to be downloaded from the server, or can be created by copying a file with the same checksum to the target location, e.g. from a trash folder. The file's content type can be retrieved from the <code>contentType</code> parameter, similar to the file's creation and modification times that are availble in the <code>created</code> and <code>modified</code> parameters.
| |
| | |
| * Example 1: Download a new file <br /> The server sends a <code>download</code> action where the file version to download is encoded in the <code>newVersion</code> paramter. The client should download and save the file as indicated by the <code>name</code> property of the <code>newVersion</code> in the directory identified by the supplied <code>path</code>. After downloading, the <code>newVersion</code> should be added to the client's known file versions database.
| |
| { | |
| "totalLength" : 536453,
| |
| "path" : "/",
| |
| "action" : "download",
| |
| "newVersion" : {
| |
| "name" : "test.pdf",
| |
| "checksum" : "3e0d7541b37d332c42a9c3adbe34aca2"
| |
| },
| |
| "contentType" : "application/pdf",
| |
| "created" : 1375276738232,
| |
| "modified" : 1375343720985
| |
| }
| |
| | |
| * Example 2: Download an updated file <br /> The server sends a <code>download</code> action where the previous file version is encoded in the <code>version</code>, and the file version to download in the <code>newVersion</code> parameter. The client should download and save the file as indicated by the <code>name</code> property of the <code>newVersion</code> in the directory identified by the supplied <code>path</code>, replacing the previous file. After downloading, the <code>newVersion</code> should be added to the client's known file versions database, replacing an existing entry for the previous <code>version</code>.
| |
| {
| |
| "totalLength" : 1599431,
| |
| "path" : "/",
| |
| "action" : "download",
| |
| "newVersion" : {
| |
| "name" : "test.pdf",
| |
| "checksum" : "bb198790904f5a1785d7402b0d8c390e"
| |
| },
| |
| "contentType" : "application/pdf",
| |
| "version" : {
| |
| "name" : "test.pdf",
| |
| "checksum" : "3e0d7541b37d332c42a9c3adbe34aca2"
| |
| },
| |
| "created" : 1375276738232,
| |
| "modified" : 1375343720985
| |
| }
| |
| | |
| === <code>upload</code> ===
| |
| Instructs the client to upload a file to the server. For updates of existing files, the previous server version is supplied in the <code>version</code> parameter, and should be used for the following <code>upload</code> request. For new files, the <code>version</code> parameter is omitted. The <code>newVersion</code> holds the target file version, i.e. filename and checksum, and should be used for the following <code>upload</code> request. When resuming a previously partly completed upload, the <code>offset</code> parameter contains the offset in bytes from which the file version should be uploaded by the client. If possible, the client should set the <code>contentType</code> parameter for the uploaded file, otherwise, the content type falls back to <code>application/octet-stream</code>.
| |
| | |
| === <code>remove</code> ===
| |
| Instructs the client to delete a file or directory version. The <code>version</code> parameter contains the version to delete. A deletion also implies a removal of the corresponding entry in the client's known versions store.
| |
| A concurrent client-side modification of the file/directory version can be detected by comparing the current checksum against the one in the passed <code>version</code> parameter.
| |
| | |
| * Example 1: Remove a file <br /> The server sends a <code>remove</code> action where the file to be removed is encoded as <code>version</code> parameter. The <code>newVersion</code> parameter is not set in the action. The client should delete the file identified by the <code>version</code> parameter. A stored checksum entry for the file in <code>version</code> should be removed, too, to reflect the changes. The <code>newVersion</code> parameter is not set in the action.
| |
| {
| |
| "path" : "/test2",
| |
| "action" : "remove",
| |
| "version" : {
| |
| "name" : "test.txt",
| |
| "checksum" : "03395a94b57eef069d248d90a9410650"
| |
| }
| |
| }
| |
| | |
| * Example 2: Remove a directory <br /> The server sends a <code>remove</code> action where the directory to be removed is encoded as <code>version</code> parameter. The <code>newVersion</code> parameter is not set in the action. The client should delete the directory identified by the <code>version</code> parameter. A stored checksum entry for the directory in <code>version</code> should be removed, too, to reflect the changes.
| |
| {
| |
| "action" : "remove",
| |
| "version" : {
| |
| "path" : "/test1",
| |
| "checksum" : "d41d8cd98f00b204e9800998ecf8427e"
| |
| }
| |
| }
| |
| | |
| === <code>sync</code> ===
| |
| The client should trigger a synchronization of the files in the directory supplied in the <code>version</code> parameter using the <code>syncfiles</code> request. A <code>sync</code> action implies the client-side creation of the referenced directory if it not yet exists, in case of a new directory on the server. \\
| |
| If the <code>version</code> parameter is not specified, a synchronization of all folders using the <code>syncfolders</code> request should be initiated by the client. \\
| |
| If the <code>reset</code> flag in the <code>SYNC</code> action is set to <code>true</code>, the client should reset his local state before synchronizing the files in the directory. This may happen when the server detects a synchronization cycle, or believes something else is going wrong. Reset means that the client should invalidate any stored original checksums for the directory itself and any contained files, so that they get re-calculated upon the next synchronization. If the <code>reset</code> flag is set in a <code>SYNC</code> action without a apecific directory version, the client should invalidate any stored checksums, so that all file- and directory-versions get re-calculated during the following synchronizations.
| |
| | |
| * Example 1: Synchronize folder <br /> The server sends a <code>sync</code> action with a <code>version</code>. The client should trigger a <code>syncfiles</code> request for the specified folder.
| |
| {
| |
| "action": "sync",
| |
| "version": {
| |
| "path": "<folder>",
| |
| "checksum": "<md5>"
| |
| }
| |
| }
| |
| | |
| * Example 2: Synchronize all folders <br /> The server sends a <code>sync</code> action without <code>version</code> (or version is //null//). The client should trigger a <code>syncfolder</code> request, i.e. the client should synchronize all folders.
| |
| {
| |
| "action": "sync",
| |
| "version": null
| |
| }
| |
| | |
| === <code>error</code> ===
| |
| With the <code>error</code> action, file- or directory versions causing a synchronization problem can be identified. The root cause of the error is encoded in the <code>error</code> parameter as described at the [[HTTP_API#Error_handling|HTTP API]].
| |
| | |
| Basically, there are two scenarios where either the errorneous version affects the synchronization state or not. For example, a file that was deleted at the client without sufficient permissions on the server can just be downloaded again by the client, and afterwards, client and server are in-sync again. On the other hand, e.g. when creating a new file at the client and this file can't be uploaded to the server due to missing permissions, the client is out of sync as long as the file is present. Therefore, the boolean parameter <code>quarantine</code> instructs the client whether the file or directory version must be excluded from the synchronization or not. If it is set to <code>true</code>, the client should exclude the version from the <code>clientVersions</code> array, and indicate the issue to the enduser. However, if the synchronization itself is not affected and the <code>quarantine</code> flag is set to <code>false</code>, the client may still indicate the issue once to the user in the background, e.g. as a balloontip notification.
| |
| | |
| The client may reset it's quarantined versions on it's own, e.g. if the user decides to "try again", or automatically after a configurable interval.
| |
| | |
| The server may also decide that further synchronization should be suspended, e.g. in case of repeated synchronization problems. Such a situation is indicated with the parameter <code>stop</code> set to <code>true</code>. In this case, the client should at least cancel the current synchronization cycle. If appropriate, the client should also be put into a 'paused' mode, and the user should be informed accordingly.
| |
| | |
| There may also be situations where a error or warning is sent to the client, independently of a file- or directory version, e.g. when the client version is outdated and a newer version is available for download.
| |
| | |
| The most common examples for errors are insufficient permissions or exceeded quota restrictions, see examples below.
| |
| | |
| * Example 1: Create a file in a read-only folder <br /> The server sends an <code>error</code> action where the errorneous file is encoded in the <code>newVersion</code> parameter and the <code>quarantine</code> flag is set to <code>true</code>. The client should exclude the version from the <code>clientVersions</code> array in upcoming <code>syncFiles</code> requests so that it doesn't affect the synchronization algorithm. The error message and further details are encoded in the <code>error</code> object of the action.
| |
| {
| |
| "error" : {
| |
| "category" : 3,
| |
| "error_params" : ["/test"],
| |
| "error" : "You are not allowed to create files at \"/test\"",
| |
| "error_id" : "1358320776-69",
| |
| "categories" : "PERMISSION_DENIED",
| |
| "code" : "DRV-0012"
| |
| },
| |
| "path" : "/test",
| |
| "quarantine" : true,
| |
| "action" : "error",
| |
| "newVersion" : {
| |
| "name" : "test.txt",
| |
| "checksum" : "3f978a5a54cef77fa3a4d3fe9a7047d2"
| |
| }
| |
| }
| |
| | |
| * Example 2: Delete a file without sufficient permissions <br /> Besides a new <code>download</code> action to restore the locally deleted file again, the server sends an <code>error</code> action where the errorneous file is encoded in the <code>version</code> parameter and the <code>quarantine</code> flag is set to <code>false</code>. Further synchronizations are not affected, but the client may still inform the user about the rejected operation. The error message and further details are encoded in the <code>error</code> object of the action.
| |
| {
| |
| "error" : {
| |
| "category" : 3,
| |
| "error_params" : ["test.png", "/test"],
| |
| "error" : "You are not allowed to delete the file \"test.png\" at \"/test\"",
| |
| "error_id" : "1358320776-74",
| |
| "categories" : "PERMISSION_DENIED",
| |
| "code" : "DRV-0011"
| |
| },
| |
| "path" : "/test",
| |
| "quarantine" : false,
| |
| "action" : "error",
| |
| "newVersion" : {
| |
| "name" : "test.png",
| |
| "checksum" : "438f06398ce968afdbb7f4db425aff09"
| |
| }
| |
| }
| |
| | |
| * Example 3: Upload a file that exceeds the quota <br /> The server sends an <code>error</code> action where the errorneous file is encoded in the <code>newVersion</code> parameter and the <code>quarantine</code> flag is set to <code>true</code>. The client should exclude the version from the <code>clientVersions</code> array in upcoming <code>syncFiles</code> requests so that it doesn't affect the synchronization algorithm. The error message and further details are encoded in the <code>error</code> object of the action.
| |
| {
| |
| "error" : {
| |
| "category" : 3,
| |
| "error_params" : [],
| |
| "error" : "The allowed Quota is reached",
| |
| "error_id" : "-485491844-918",
| |
| "categories" : "PERMISSION_DENIED",
| |
| "code" : "DRV-0016"
| |
| },
| |
| "path" : "/",
| |
| "quarantine" : true,
| |
| "action" : "error",
| |
| "newVersion" : {
| |
| "name" : "test.txt",
| |
| "checksum" : "0ca6033e2a9c2bea1586a2984bf111e6"
| |
| }
| |
| }
| |
| | |
| * Example 4: Synchronize with a client where the version is no longer supported. <br /> The server sends an <code>error</code> action with code <code>DRV-0028</code> and an appropriate error message. The <code>stop</code> flag is set to <code>true</code> to interrupt the synchronization cycle.
| |
| {
| |
| "stop" : true,
| |
| "error" : {
| |
| "category" : 13,
| |
| "error_params" : [],
| |
| "error" : "The client application you're using is outdated and no longer supported - please upgrade to a newer version.",
| |
| "error_id" : "103394512-13",
| |
| "categories" : "WARNING",
| |
| "code" : "DRV-0028",
| |
| "error_desc" : "Client outdated - current: \"0.9.2\", required: \"0.9.10\""
| |
| },
| |
| "quarantine" : false,
| |
| "action" : "error"
| |
| }
| |
| | |
| * Example 5: Synchronize with a client where a new version of the client application is available. <br /> The server sends an <code>error</code> action with code <code>DRV-0029</code> and an appropriate error message. The <code>stop</code> flag is set to <code>false</code> to indicate that the synchronization can continue.
| |
| {
| |
| "stop" : false,
| |
| "error" : {
| |
| "category" : 13,
| |
| "error_params" : [],
| |
| "error" : "A newer version of your client application is available for download.",
| |
| "error_id" : "103394512-29",
| |
| "categories" : "WARNING",
| |
| "code" : "DRV-0029",
| |
| "error_desc" : "Client update available - current: \"0.9.10\", available: \"0.9.12\""
| |
| },
| |
| "quarantine" : false,
| |
| "action" : "error"
| |
| }
| |
|
| |
| == Synchronize folders ==
| |
| | |
| This request performs the synchronization of all folders, resulting in different actions that should be executed on the client afterwards. This operation typically serves as an entry point for a synchronization cycle.
| |
| | |
| PUT <code>/ajax/drive?action=syncfolders</code>
| |
| | |
| Parameters:
| |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>version</code> - The current client version (matching the pattern <code>^[0-9]+(\\.[0-9]+)*$</code>). If not set, the initial version <code>0</code> is assumed.
| |
| * <code>apiVersion</code> - The API version that the client is using. If not set, the initial version <code>0</code> is assumed.
| |
| * <code>diagnostics</code> (optional) - If set to <code>true</code>, an additional diagnostics trace is supplied in the response.
| |
| * <code>pushToken</code> (optional) - The client's push registration token to associate it to generated events.
| |
| | |
| Request Body: <br />
| |
| A JSON object containing two JSON arrays named <code>clientVersions</code> and <code>originalVersions</code>. The client versions array lists all current directories below the root directory as a flat list, encoded as [[#Directory_Version|Directory Versions]]. The original versions array contains all previously known directories, i.e. all previously synchronized and acknowledged directories, also encoded as [[#Directory_Version|Directory Versions]]. \\
| |
| Optionally, available since API version 2, the JSON object may also contain two arrays named <code>fileExclusions</code> and <code>directoryExclusions</code> to define client-side exclusion filters, with each element encoded as [[#File_pattern|File patterns]] and [[#Directory_pattern|Directory patterns]] accordingly. See [[#Client_side_filtering]] for details.
| |
| | |
| Response: <br />
| |
| A JSON array containing all actions the client should execute for synchronization. Each array element is an action as described in [[#Actions | Actions]]. <br /> If the <code>diagnostics</code> flag was set (either to <code>true</code> or <code>false</code>), this array is wrapped into an additional JSON object in the <code>actions</code> parameter, and the diagnostics trace is provided at <code>diagnostics</code>.
| |
| | |
| Example:
| |
| ==> PUT http://192.168.32.191/ajax/drive?action=syncfolders&root=56&session=5d0c1e8eb0964a3095438b450ff6810f
| |
| > Content:
| |
| {
| |
| "clientVersions" : [{
| |
| "path" : "/",
| |
| "checksum" : "7b744b13df4b41006495e1a15327368a"
| |
| }, {
| |
| "path" : "/test1",
| |
| "checksum" : "3ecc97334d7f6bf2b795988092b8137e"
| |
| }, {
| |
| "path" : "/test2",
| |
| "checksum" : "56534fc2ddcb3b7310d3ef889bc5ae18"
| |
| }, {
| |
| "path" : "/test2/test3",
| |
| "checksum" : "c193fae995d9f9431986dcdc3621cd98"
| |
| }
| |
| ],
| |
| "originalVersions" : [{
| |
| "path" : "/",
| |
| "checksum" : "7b744b13df4b41006495e1a15327368a"
| |
| }, {
| |
| "path" : "/test2/test3",
| |
| "checksum" : "c193fae995d9f9431986dcdc3621cd98"
| |
| }, {
| |
| "path" : "/test2",
| |
| "checksum" : "35d1b51fdefbee5bf81d7ae8167719b8"
| |
| }, {
| |
| "path" : "/test1",
| |
| "checksum" : "3ecc97334d7f6bf2b795988092b8137e"
| |
| }
| |
| ]
| |
| }
| |
|
| |
| <== HTTP 200 OK (8.0004 ms elapsed, 102 bytes received)
| |
| < Content:
| |
| {
| |
| "data" : [{
| |
| "action" : "sync",
| |
| "version" : {
| |
| "path" : "/test2",
| |
| "checksum" : "56534fc2ddcb3b7310d3ef889bc5ae18"
| |
| }
| |
| }
| |
| ]
| |
| }
| |
| | |
| Example 2:
| |
| ==> PUT http://192.168.32.191/ajax/drive?action=syncfolders&root=56&session=5d0c1e8eb0964a3095438b450ff6810f
| |
| > Content:
| |
| {
| |
| "clientVersions" : [{
| |
| "path" : "/",
| |
| "checksum" : "7b744b13df4b41006495e1a15327368a"
| |
| }, {
| |
| "path" : "/test1",
| |
| "checksum" : "3ecc97334d7f6bf2b795988092b8137e"
| |
| }, {
| |
| "path" : "/test2",
| |
| "checksum" : "56534fc2ddcb3b7310d3ef889bc5ae18"
| |
| }, {
| |
| "path" : "/test2/test3",
| |
| "checksum" : "c193fae995d9f9431986dcdc3621cd98"
| |
| }
| |
| ],
| |
| "originalVersions" : [{
| |
| "path" : "/",
| |
| "checksum" : "7b744b13df4b41006495e1a15327368a"
| |
| }, {
| |
| "path" : "/test2/test3",
| |
| "checksum" : "c193fae995d9f9431986dcdc3621cd98"
| |
| }, {
| |
| "path" : "/test2",
| |
| "checksum" : "35d1b51fdefbee5bf81d7ae8167719b8"
| |
| }, {
| |
| "path" : "/test1",
| |
| "checksum" : "3ecc97334d7f6bf2b795988092b8137e"
| |
| }
| |
| ]
| |
| "fileExclusions" : [{
| |
| "path" : "/",
| |
| "name" : "excluded.txt",
| |
| "type" : "exact"
| |
| }
| |
| ], "directoryExclusions" : [{
| |
| "path" : "/temp",
| |
| "type" : "exact"
| |
| }, {
| |
| "path" : "/temp/*",
| |
| "type" : "glob"
| |
| }
| |
| ]
| |
| }
| |
|
| |
| <== HTTP 200 OK (8.0004 ms elapsed, 102 bytes received)
| |
| < Content: | |
| {
| |
| "data" : [{
| |
| "action" : "sync",
| |
| "version" : {
| |
| "path" : "/test2",
| |
| "checksum" : "56534fc2ddcb3b7310d3ef889bc5ae18"
| |
| }
| |
| }
| |
| ]
| |
| }
| |
| | |
| | |
| == Synchronize files in a folder ==
| |
| | |
| This request performs the synchronization of a single folder, resulting in different actions that should be executed on the client afterwards. This action is typically executed as result of a <code>syncfolders</code> action.
| |
| | |
| PUT <code>/ajax/drive?action=syncfiles</code>
| |
| | |
| Parameters:
| |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>path</code> - The path to the synchronized folder, relative to the root folder.
| |
| * <code>device</code> (optional) - A friendly name identifying the client device from a user's point of view, e.g. "My Tablet PC".
| |
| * <code>apiVersion</code> - The API version that the client is using. If not set, the initial version <code>0</code> is assumed.
| |
| * <code>diagnostics</code> (optional) - If set to <code>true</code>, an additional diagnostics trace is supplied in the response.
| |
| * <code>columns</code> (optional) - A comma-separated list of columns representing additional metadata that is relevant for the client. Each column is specified by a numeric column identifier. Column identifiers for file metadata are defined in [[#File Metadata]]. If available, the requested metadata of files is included in the corresponsing <code>DOWNLOAD</code> and <code>ACKNOWLEDGE</code> actions (deprecated, available until API version 2).
| |
| * <code>pushToken</code> (optional) - The client's push registration token to associate it to generated events.
| |
| | |
| Request Body: <br />
| |
| A JSON object containing two JSON arrays named <code>clientVersions</code> and <code>originalVersions</code>. The client versions array lists all current files in the client directory, encoded as [[#File Version | File Versions]]. The original versions array contains all previously known files, i.e. all previously synchronized and acknowledged files, also encoded as [[#File Version | File Versions]]. \\
| |
| Optionally, available since API version 2, the JSON object may also contain an array named <code>fileExclusions</code> to define client-side exclusion filters, with each element encoded as [[#File pattern | File patterns]]. See [[#Client side filtering]] for details.
| |
| | |
| Response: <br />
| |
| A JSON array containing all actions the client should execute for synchronization. Each array element is an action as described in [[#Actions | Actions]]. <br /> If the <code>diagnostics</code> flag was set (either to <code>true</code> or <code>false</code>), this array is wrapped into an additional JSON object in the <code>actions</code> parameter, and the diagnostics trace is provided at <code>diagnostics</code>.
| |
| | |
| Example:
| |
| ==> PUT http://192.168.32.191/ajax/drive?action=syncfiles&root=56&path=/test2&device=Laptop&session=5d0c1e8eb0964a3095438b450ff6810f
| |
| > Content:
| |
| {
| |
| "clientVersions" : [{
| |
| "name" : "Jellyfish.jpg",
| |
| "checksum" : "5a44c7ba5bbe4ec867233d67e4806848"
| |
| }, {
| |
| "name" : "Penguins.jpg",
| |
| "checksum" : "9d377b10ce778c4938b3c7e2c63a229a"
| |
| }
| |
| ],
| |
| "originalVersions" : [{
| |
| "name" : "Jellyfish.jpg",
| |
| "checksum" : "5a44c7ba5bbe4ec867233d67e4806848"
| |
| }
| |
| ]
| |
| }
| |
| | | |
| <== HTTP 200 OK (6.0004 ms elapsed, 140 bytes received) | | # The password used when joining the cluster. Defaults to "wtV6$VQk8#+3ds!a". |
| < Content:
| | # Please change this value, and ensure it's equal on all nodes in the cluster. |
| {
| | com.openexchange.hazelcast.group.password=wtV6$VQk8#+3ds!a |
| "data" : [{
| |
| "path" : "/test2",
| |
| "action" : "upload",
| |
| "newVersion" : {
| |
| "name" : "Penguins.jpg",
| |
| "checksum" : "9d377b10ce778c4938b3c7e2c63a229a"
| |
| },
| |
| "offset" : 0
| |
| }
| |
| ]
| |
| }
| |
|
| |
|
| Example 2:
| | == Network == |
| ==> PUT http://192.168.32.191/ajax/drive?action=syncfiles&root=56&path=/test2&device=Laptop&session=5d0c1e8eb0964a3095438b450ff6810f
| |
| > Content:
| |
| {
| |
| "clientVersions" : [{
| |
| "name" : "Jellyfish.jpg",
| |
| "checksum" : "5a44c7ba5bbe4ec867233d67e4806848"
| |
| }, {
| |
| "name" : "Penguins.jpg",
| |
| "checksum" : "9d377b10ce778c4938b3c7e2c63a229a"
| |
| }
| |
| ],
| |
| "originalVersions" : [{
| |
| "name" : "Jellyfish.jpg",
| |
| "checksum" : "5a44c7ba5bbe4ec867233d67e4806848"
| |
| }
| |
| ]
| |
| "fileExclusions" : [{
| |
| "path" : "*",
| |
| "name" : "*.tmp",
| |
| "type" : "glob"
| |
| }
| |
| ]
| |
| }
| |
|
| |
| <== HTTP 200 OK (6.0004 ms elapsed, 140 bytes received)
| |
| < Content:
| |
| {
| |
| "data" : [{
| |
| "path" : "/test2",
| |
| "action" : "upload",
| |
| "newVersion" : {
| |
| "name" : "Penguins.jpg",
| |
| "checksum" : "9d377b10ce778c4938b3c7e2c63a229a"
| |
| },
| |
| "offset" : 0
| |
| }
| |
| ]
| |
| }
| |
|
| |
|
| == Download a file ==
| | It's required to define the network interface that is used for cluster communication via ''com.openexchange.hazelcast.network.interfaces''. By default, the interface is restricted to the local loopback address only. To allow the same configuration amongst all nodes in the cluster, it's recommended to define the value using a wildcard matching the IP addresses of all nodes participating in the cluster, e.g. ''192.168.0.*'' |
|
| |
|
| Downloads a file from the server.
| | # Comma-separated list of interface addresses hazelcast should use. Wildcards |
| | # (*) and ranges (-) can be used. Leave blank to listen on all interfaces |
| | # Especially in server environments with multiple network interfaces, it's |
| | # recommended to specify the IP-address of the network interface to bind to |
| | # explicitly. Defaults to "127.0.0.1" (local loopback only), needs to be |
| | # adjusted when building a cluster of multiple backend nodes. |
| | com.openexchange.hazelcast.network.interfaces=127.0.0.1 |
|
| |
|
| GET <code>/ajax/drive?action=download</code>
| | To form a cluster of multiple OX server nodes, different discovery mechanisms can be used. The discovery mechanism is specified via the property ''com.openexchange.hazelcast.network.join'': |
|
| |
|
| or | | # Specifies which mechanism is used to discover other backend nodes in the |
| | # cluster. Possible values are "empty" (no discovery for single-node setups), |
| | # "static" (fixed set of cluster member nodes) or "multicast" (automatic |
| | # discovery of other nodes via multicast). Defaults to "empty". Depending on |
| | # the specified value, further configuration might be needed, see "Networking" |
| | # section below. |
| | com.openexchange.hazelcast.network.join=empty |
|
| |
|
| PUT <code>/ajax/drive?action=download</code>
| | Generally, it's advised to use the same network join mechanism for all nodes in the cluster, and, in most cases, it's strongly recommended to use a ''static'' network join configuration. This will allow the nodes to join the cluster directly upon startup. With a ''multicast'' based setup, nodes will merge to an existing cluster possibly at some later time, thus not being able to access the distributed data until they've joined. |
|
| |
|
| Parameters:
| | Depending on the network join setting, further configuration may be necessary, as decribed in the following paragraphs. |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>path</code> - The path to the synchronized folder, relative to the root folder.
| |
| * <code>name</code> - The name of the file version to download.
| |
| * <code>checksum</code> - The checksum of the file version to download.
| |
| * <code>apiVersion</code> - The API version that the client is using. If not set, the initial version <code>0</code> is assumed.
| |
| * <code>offset</code> (optional) - The start offset in bytes for the download. If not defined, an offset of <code>0</code> is assumed.
| |
| * <code>length</code> (optional) - The number of bytes to include in the download stream. If not defined, the file is read until the end.
| |
|
| |
|
| Request Body: <br />
| | === empty === |
| Optionally, available since API version 3, if client-side file- and/or directory exclusion filters are active, a PUT request can be used. The request body then holds a JSON object containing two arrays named <code>fileExclusions</code> and <code>directoryExclusions</code> to define client-side exclusion filters, with each element encoded as [[File_pattern|File patterns]] and [[Directory_pattern|Directory patterns]] accordingly. See [[Client_side_filtering|Client side filtering]] for details.
| |
|
| |
|
| Response: <br />
| | When using the default value ''empty'', no other nodes are discovered in the cluster. This value is suitable for single-node installations. Note that other nodes that are configured to use other network join mechanisms may be still able to still to connect to this node, e.g. using a ''static'' network join, having the IP address of this host in the list of potential cluster members (see below). |
| The binary content of the requested file version. Note that in case of errors, an exception is not encoded in the default JSON error format here. Instead, an appropriate HTTP error with a status code != 200 is returned. For example, in case of the requested file being deleted or modified in the meantime, a response with HTTP status code 404 (not found) is sent.
| |
|
| |
|
| Example:
| | === static === |
| ==> GET http://192.168.32.191/ajax/drive?action=download&root=56&path=/test2&name=Jellyfish.jpg&checksum=5a44c7ba5bbe4ec867233d67e4806848&offset=0&length=-1&session=5d0c1e8eb0964a3095438b450ff6810f
| |
|
| |
| <== HTTP 200 OK (20.0011 ms elapsed, 775702 bytes received)
| |
|
| |
|
| == Upload a file ==
| | The most common setting for ''com.openexchange.hazelcast.network.join'' is ''static''. A static cluster discovery uses a fixed list of IP addresses of the nodes in the cluster. During startup and after a specific interval, the underlying Hazelcast library probes for not yet joined nodes from this list and adds them to the cluster automatically. The address list is configured via ''com.openexchange.hazelcast.network.join.static.nodes'': |
|
| |
|
| Uploads a file to the server.
| | # Configures a comma-separated list of IP addresses / hostnames of possible |
| | # nodes in the cluster, e.g. "10.20.30.12, 10.20.30.13:5701, 192.178.168.110". |
| | # Only used if "com.openexchange.hazelcast.network.join" is set to "static". |
| | # It doesn't hurt if the address of the local host appears in the list, so |
| | # that it's still possible to use the same list throughout all nodes in the |
| | # cluster. |
| | com.openexchange.hazelcast.network.join.static.nodes= |
|
| |
|
| PUT <code>/ajax/drive?action=upload</code>
| | For a fixed set of backend nodes, it's recommended to simply include the IP addresses of all nodes in the list, and use the same configuration for each node. However, it's only required to add the address of at least one other node in the cluster to allow the node to join the cluster. Also, when adding a new node to the cluster and this list is extended accordingly, existing nodes don't need to be shut down to recognize the new node, as long as the new node's address list contains at least one of the already running nodes. |
|
| |
|
| Parameters:
| | === multicast === |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>path</code> - The path to the synchronized folder, relative to the root folder.
| |
| * <code>newName</code> - The target name of the file version to upload.
| |
| * <code>newChecksum</code> - The target checksum of the file version to upload.
| |
| * <code>name</code> (optional) - The previous name of the file version being uploaded. Only set when uploading an updated version of an existing file to the server.
| |
| * <code>checksum</code> - The previous checksum of the file version to upload. Only set when uploading an updated version of an existing file to the server.
| |
| * <code>apiVersion</code> - The API version that the client is using. If not set, the initial version <code>0</code> is assumed.
| |
| * <code>contentType</code> (optional) - The content type of the file. If not defined, <code>application/octet-stream</code> is assumed.
| |
| * <code>offset</code> (optional) - The start offset in bytes for the upload when resuming a previous partial upload. If not defined, an offset of <code>0</code> is assumed.
| |
| * <code>totalLength</code> (optional) - The total expected length of the file (required to support resume of uploads). If not defined, the upload is assumed completed after the operation.
| |
| * <code>created</code> (optional) - The creation time of the file as timestamp.
| |
| * <code>modified</code> (optional) - The last modification time of the file as timestamp. Defaults to the current server time if no value or a value larger than the current time is supplied.
| |
| * <code>binary</code> - Expected to be set to <code>true</code> to indicate the binary content.
| |
| * <code>device</code> (optional) - A friendly name identifying the client device from a user's point of view, e.g. "My Tablet PC".
| |
| * <code>diagnostics</code> (optional) - If set to <code>true</code>, an additional diagnostics trace is supplied in the response.
| |
| * <code>pushToken</code> (optional) - The client's push registration token to associate it to generated events.
| |
|
| |
|
| Request body: <br />
| | For highly dynamic setups where nodes are added and removed from the cluster quite often and/or the host's IP addresses are not fixed, it's also possible to configure the network join via multicast. During startup and after a specific interval, the backend nodes initiate the multicast join process automatically, and discovered nodes form or join the cluster afterwards. The multicast group and port can be configured as follows: |
| The binary content of the uploaded file version.
| |
|
| |
|
| Response: <br />
| | # Configures the multicast address used to discover other nodes in the cluster |
| A JSON array containing all actions the client should execute for synchronization. Each array element is an action as described in [[#Actions | Actions]]. <br /> If the <code>diagnostics</code> flag was set (either to <code>true</code> or <code>false</code>), this array is wrapped into an additional JSON object in the <code>actions</code> parameter, and the diagnostics trace is provided at <code>diagnostics</code>.
| | # dynamically. Only used if "com.openexchange.hazelcast.network.join" is set |
| | | # to "multicast". If the nodes reside in different subnets, please ensure that |
| Example:
| | # multicast is enabled between the subnets. Defaults to "224.2.2.3". |
| ==> PUT http://192.168.32.191/ajax/drive?action=upload&root=56&path=/test2&newName=Penguins.jpg&newChecksum=9d377b10ce778c4938b3c7e2c63a229a&contentType=image/jpeg&offset=0&totalLength=777835&binary=true&device=Laptop&created=1375343426999&modified=1375343427001&session=5d0c1e8eb0964a3095438b450ff6810f | | com.openexchange.hazelcast.network.join.multicast.group=224.2.2.3 |
| > Content:
| |
| [application/octet-stream;, 777835 bytes]
| |
| | | |
| <== HTTP 200 OK (108.0062 ms elapsed, 118 bytes received) | | # Configures the multicast port used to discover other nodes in the cluster |
| < Content: | | # dynamically. Only used if "com.openexchange.hazelcast.network.join" is set |
| {
| | # to "multicast". Defaults to "54327". |
| "data" : [{
| | com.openexchange.hazelcast.network.join.multicast.port=54327 |
| "action" : "acknowledge",
| |
| "newVersion" : {
| |
| "name" : "Penguins.jpg",
| |
| "checksum" : "9d377b10ce778c4938b3c7e2c63a229a"
| |
| }
| |
| }
| |
| ]
| |
| }
| |
| | |
| == Listen for changes (long polling) ==
| |
| | |
| Listens for server-side changes. The request blocks until new actions for the client are available, or the specified waiting time elapses. May return immediately if previously received but not yet processed actions are available for this client.
| |
| | |
| GET <code>/ajax/drive?action=listen</code>
| |
|
| |
|
| Parameters:
| | == Example == |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>timeout</code> (optional) - The maximum timeout in milliseconds to wait.
| |
| * <code>pushToken</code> (optional) - The client's push registration token to associate it to generated events.
| |
|
| |
|
| Response: <br />
| | The following example shows how a simple cluster named ''MyCluster'' consisting of 4 backend nodes can be configured using ''static'' cluster discovery. The node's IP addresses are 10.0.0.15, 10.0.0.16, 10.0.0.17 and 10.0.0.18. Note that the same ''hazelcast.properties'' is used by all nodes. |
| A JSON array containing all actions the client should execute for synchronization. Each array element is an action as described in [[#Actions | Actions]]. If there no changes were detected, an empty array is returned. Typically, the client will continue with the next <code>listen</code> request after the response was processed.
| |
|
| |
|
| Example:
| | com.openexchange.hazelcast.group.name=MyCluster |
| ==> GET http://192.168.32.191/ajax/drive?action=listen&root=65841&session=51378e29f82042b4afe4af1c034c6d68 | | com.openexchange.hazelcast.group.password=secret |
| | | com.openexchange.hazelcast.network.join=static |
| <== HTTP 200 OK (63409.6268 ms elapsed, 28 bytes received) | | com.openexchange.hazelcast.network.join.static.nodes=10.0.0.15,10.0.0.16,10.0.0.17,10.0.0.18 |
| < Content: | | com.openexchange.hazelcast.network.interfaces=10.0.0.* |
| {
| |
| "data" : [{
| |
| "action" : "sync",
| |
| }
| |
| ]
| |
| }
| |
|
| |
|
| == Get quota ==
| |
|
| |
|
| Gets the quota limits and current usage for the storage the supplied root folder belongs to. Depending on the filestore configuration, this may include both restrictions on the number of allowed files and the total size of all contained files in bytes. If there's no limit, -1 is returned.
| | == Advanced Configuration == |
|
| |
|
| GET <code>/ajax/drive?action=quota</code>
| | === Custom Partitioning (preliminary) === |
|
| |
|
| Parameters:
| | While originally being desgined to separate the nodes holding distributed data into different risk groups for increased fail safety, a custom partioning strategy may also be used to distinguish between nodes holding distributed data from those who should not. |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
|
| |
|
| Response: <br />
| | This approach of custom partitioning may be used in a OX cluster, where usually different backend nodes serve different purposes. A common scenario is that there are nodes handling requests from the web interfaces, and others being responsible for USM/EAS traffic. Due to their nature of processing large chunks of synchronization data in memory, the USM/EAS nodes may encounter small delays when the Java garbage collector kicks in and suspends the Java Virtual Machine. Since those delays may also have an influence on hazelcast-based communication in the cluster, the idea is to instruct hazelcast to not store distributed data on that nodes. This is where a custom partitioning scheme comes into play. |
| A JSON object containing the quota restrictions inside a JSON array with the property name <code>quota</code>. The JSON array contains zero, one or two <code>quota</code> objects as described below, depending on the filestore configuration. If one or more quota <code>type</code>s are missing in the array, the client can expect that there are no limitations for that type. Besides the array, the JSON object also contains a hyperlink behind the <code>manageLink</code> parameter, pointing to an URL where the user could manage his quota restrictions. | |
|
| |
|
| {| id="Quota" cellspacing="0" border="1"
| | To setup a custom paritioning scheme in the cluster, an additional ''hazelcast.xml'' configuration file is used, which should be placed into the ''hazelcast'' subdirectory of the OX configuration folder, usually at ''/opt/openexchange/etc/hazelcast''. Please note that it's vital that each node in the cluster is configured equally here, so the same ''hazelcast.xml'' file should be copied to each server. The configuration read from there is used as basis for all further settings that are taken from the ordinary ''hazelcast.properties'' config file. |
| |+ align="bottom" | Quota
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | limit || Number || The allowed limit (either number of files or sum of filesizes in bytes).
| |
| |-
| |
| | use || Number || The current usage (again either number of files or sum of filesizes in bytes).
| |
| |-
| |
| | type || String || The kind of quota restriction, currently either <code>storage</code> (size of contained files in bytes) or <code>file</code> (number of files).
| |
| |}
| |
|
| |
|
| Example:
| | To setup a custom paritioning scheme, the partition groups must be defined in the ''hazelcast.xml'' file. See the following file for an example configuration, where the three nodes ''10.10.10.60'', ''10.10.10.61'' and ''10.10.10.62'' are defined to form an own paritioning group each. Doing so, all distributed data will be stored at one of those nodes physically, while the corresponding backup data (if configured) at one of the other two nodes. All other nodes in the cluster will not be used to store distributed data, but will still be "full" hazelcast members, which is necessary for other cluster-wide operations the OX backends use. |
| ==> GET http://192.168.32.191/ajax/drive?action=quota&root=56&session=35cb8c2d1423480692f0d5053d14ba52
| |
|
| |
| <== HTTP 200 OK (9.6854 ms elapsed, 113 bytes received)
| |
| < Content:
| |
| {
| |
| "data" : {
| |
| "quota" : [{
| |
| "limit" : 107374182400,
| |
| "use" : 1109974882,
| |
| "type" : "storage"
| |
| }, {
| |
| "limit" : 800000000000,
| |
| "use" : 1577,
| |
| "type" : "file"
| |
| }
| |
| ],
| |
| "manageLink" : "https://www.example.com/manageQuota"
| |
| }
| |
| }
| |
|
| |
|
| == Get Settings ==
| | Please note that the configured backup count in the map configurations should be smaller than the number of nodes here, otherwise, there may be problems if one of those data nodes is shut down temporarily for maintenance. So, the minimum number of nodes to define in the partition group sections is implicitly bound to the sum of a map's ''backupCount'' and ''asyncBackupCount'' properties, plus ''1'' for the original data partition. |
|
| |
|
| Gets various settings applicable for the drive clients.
| |
|
| |
|
| GET <code>/ajax/drive?action=settings</code>
| | <?xml version="1.0" encoding="UTF-8"?> |
| | | <!-- |
| Parameters:
| | ~ Copyright (c) 2008-2013, Hazelcast, Inc. All Rights Reserved. |
| * <code>session</code> - A session ID previously obtained from the login module.
| | ~ |
| * <code>root</code> - The ID of the referenced root folder on the server.
| | ~ Licensed under the Apache License, Version 2.0 (the "License"); |
| * <code>language</code> (optional) - The locale to use for language-sensitive settings (in the format <code><2-letter-language>_<2-letter-region></code>, e.g. <code>de_CH</code> or <code>en_GB</code>). Defaults to the user's configured locale on the server.
| | ~ you may not use this file except in compliance with the License. |
| | | ~ You may obtain a copy of the License at |
| Response:<br />
| | ~ |
| A JSON object holding the settings as described below. This also includes a JSON array with the property name <code>quota</code> that contains zero, one or two quota objects as described below, depending on the filestore configuration. If one or more quota types are missing in the array, the client can expect that there are no limitations for that type.
| | ~ http://www.apache.org/licenses/LICENSE-2.0 |
| | | ~ |
| {| id="Quota" cellspacing="0" border="1"
| | ~ Unless required by applicable law or agreed to in writing, software |
| |+ align="bottom" | Quota
| | ~ distributed under the License is distributed on an "AS IS" BASIS, |
| ! Name !! Type !! Value
| | ~ WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. |
| |-
| | ~ See the License for the specific language governing permissions and |
| | limit || Number || The allowed limit (either number of files or sum of filesizes in bytes).
| | ~ limitations under the License. |
| |-
| | --> |
| | use || Number || The current usage (again either number of files or sum of filesizes in bytes).
| |
| |-
| |
| | type || String || The kind of quota restriction, currently either <code>storage</code> (size of contained files in bytes) or <code>file</code> (number of files).
| |
| |}
| |
| | |
| {| id="Settings" cellspacing="0" border="1"
| |
| |+ align="bottom" | Settings
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | helpLink || String || A hyperlink to the online help.
| |
| |-
| |
| | quotaManageLink || String || A hyperlink to an URL where the user could manage his quota restrictions.
| |
| |-
| |
| | quota || Array || A JSON array containing the quota restrictions as described above.
| |
| |-
| |
| | serverVersion || String || The server version string.
| |
| |-
| |
| | supportedApiVersion || String || The API version supported by the server.
| |
| |-
| |
| | minApiVersion || String || The API version required to synchronize with the server.
| |
| |}
| |
| | |
| Example:
| |
| ==> GET http://192.168.32.191/ajax/drive?action=settings&root=56&session=35cb8c2d1423480692f0d5053d14ba52
| |
| | |
| <== HTTP 200 OK (11.3530 ms elapsed, 318 bytes received)
| |
| < Content:
| |
| {
| |
| "data" : {
| |
| "quota" : [{
| |
| "limit" : 107374182400,
| |
| "use" : 8828427,
| |
| "type" : "storage"
| |
| }, {
| |
| "limit" : 800000000000,
| |
| "use" : 1559,
| |
| "type" : "file"
| |
| }
| |
| ],
| |
| "helpLink" : "http://192.168.32.191/ajax/help/en_US/index.html",
| |
| "quotaManageLink" : "https://192.168.32.191/manageQuota",
| |
| "serverVersion" : "7.4.2-Rev1",
| |
| "supportedApiVersion" : "2",
| |
| "minApiVersion" : "1"
| |
| }
| |
| }
| |
| | |
| == Subscribe to Push-Events ==
| |
| | |
| Registers a client device to receive push notifications from the server. The subscription is performed based on the configured root folder ID of the client application that identifies itself with it's device token. Supported services currently include the Apple Push Notification Service (APN) and Google Cloud Messaging (GCM). Trying to perform an identical subscription (same <code>root</code>, <code>service</code> and <code>token</code>) from the same user account again is treated as a no-op.
| |
| | |
| GET <code>/ajax/drive?action=subscribe</code>
| |
| | |
| Parameters:
| |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>service</code> - The name of the underlying push service to use, currently one of <code>gcm</code>, <code>apn</code> or <code>apn.macos</code>.
| |
| * <code>token</code> - The device's registration token as assigned by the service.
| |
| | |
| Response:<br />
| |
| An empty JSON result.
| |
| | |
| Example:
| |
| ==> GET http://192.168.32.191/ajax/drive?action=subscribe&root=65841&session=51378e29f82042b4afe4af1c034c6d68&service=apn&token=28919862989a1b5ba59c11d5f7cb7ba2b9678be9dd18b033184d04f682013677
| |
| | | |
| <== HTTP 200 OK (13.6268 ms elapsed, 11 bytes received) | | <hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.1.xsd" |
| < Content:
| | xmlns="http://www.hazelcast.com/schema/config" |
| { | | xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"> |
| "data" : {
| | <partition-group enabled="true" group-type="CUSTOM"> |
| }
| | <member-group> |
| } | | <interface>10.10.10.60</interface> |
| | </member-group> |
| | <member-group> |
| | <interface>10.10.10.61</interface> |
| | </member-group> |
| | <member-group> |
| | <interface>10.10.10.62</interface> |
| | </member-group> |
| | </partition-group> |
| | </hazelcast> |
|
| |
|
| | More general information regarding custom partioning is available at http://hazelcast.org/docs/latest/manual/html/partitiongroupconfig.html . |
|
| |
|
| == Unsubscribe from Push-Events ==
| | It's also recommended to use a "static" cluster discovery for the network join, and list same the nodes that are also configured in the parition groups here, so that join requests are handled by those nodes, too (and not the other nodes that are potentially prone to garbage collection delays. |
|
| |
|
| Unregisters a previously registered client device to stop receiving push notifications from the server. The same parameters that were used to perform the subscription need to be passed again, which includes the root folder ID, the device token and the service name.
| | After configuring a custom paritioning scheme, the data distribution may be verified, e.g. by inspecting the MBeans of the distributed maps via JMX. |
|
| |
|
| GET <code>/ajax/drive?action=unsubscribe</code>
| | = Features = |
|
| |
|
| Parameters:
| | The following list gives an overview about different features that were implemented using the new cluster capabilities. |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>service</code> - The name of the underlying push service to use, currently one of <code>gcm</code>, <code>apn</code> or <code>apn.macos</code>.
| |
| * <code>token</code> - The device's registration token as assigned by the service.
| |
|
| |
|
| Response:<br />
| | == Distributed Session Storage == |
| An empty JSON result.
| |
|
| |
|
| Example:
| | Previously, when an Open-Xchange server was shutdown for maintenance, all user sessions that were bound to that machine were lost, i.e. the users needed to login again. With the distributed session storage, all sessions are backed by a distributed map in the cluster, so that they are no longer bound to a specific node in the cluster. When a node is shut down, the session data is still available in the cluster and can be accessed from the remaining nodes. The load-balancing techniques of the webserver then seamlessly routes the user session to another node, with no ''session expired'' errors. The distributed session storage comes with the package ''open-xchange-sessionstorage-hazelcast''. It's recommended to install this optional package in all clustered environments with multiple groupware server nodes. |
| ==> GET http://192.168.32.191/ajax/drive?action=unsubscribe&root=65841&session=51378e29f82042b4afe4af1c034c6d68&service=apn&token=28919862989a1b5ba59c11d5f7cb7ba2b9678be9dd18b033184d04f682013677
| |
|
| |
| <== HTTP 200 OK (26.0015 ms elapsed, 11 bytes received)
| |
| < Content:
| |
| {
| |
| "data" : {
| |
| }
| |
| }
| |
|
| |
|
| == Update the subscription token ==
| | '''Note:''' While there's some kind of built-in session distribution among the nodes in the cluster, this should not be seen as a replacement for session-stickiness between the loadbalancer and groupware nodes, i.e. one should still configure the webserver to use sticky sessions for performance reasons. |
|
| |
|
| Updates a device's registration token in case a new one was assigned by the service.
| | Depending on the cluster infrastructure, different backup-count configuration options might be set for the distributed session storage in the map configuration file ''sessions.properties'' in the ''hazelcast'' subdirectory: |
|
| |
|
| GET <code>/ajax/drive?action=updateToken</code>
| | com.openexchange.hazelcast.configuration.map.backupCount=1 |
|
| |
|
| Parameters:
| | The ''backupcount'' property configures the number of nodes with synchronized backups. Synchronized backups block operations until backups are successfully copied and acknowledgements are received. If 1 is set as the backup-count for example, then all entries of the map will be copied to another JVM for fail-safety. 0 means no backup. Any integer between 0 and 6. Default is 1, setting bigger than 6 has no effect. |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>service</code> - The name of the underlying push service to use, currently one of <code>gcm</code>, <code>apn</code> or <code>apn.macos</code>.
| |
| * <code>token</code> - The previous registration token as assigned by the service.
| |
| * <code>newToken</code> - The new registration token as assigned by the service.
| |
|
| |
|
| Response:<br />
| | com.openexchange.hazelcast.configuration.map.asyncBackupCount=0 |
| An empty JSON result.
| |
|
| |
|
| Example:
| | The ''asyncbackup'' property configures the number of nodes with async backups. Async backups do not block operations and do not require acknowledgements. 0 means no backup. Any integer between 0 and 6. Default is 0, setting bigger than 6 has no effect. |
| ==> GET http://192.168.32.191/ajax/drive?action=updateToken&service=apn&session=51378e29f82042b4afe4af1c034c6d68&token=28919862989a1b5ba59c11d5f7cb7ba2b9678be9dd18b033184d04f682013677&newToken=38919862989a1b5ba59c11d5f7cb7ba2b9678be9dd18b033184d04f682013677
| |
|
| |
| <== HTTP 200 OK (15.6653 ms elapsed, 11 bytes received)
| |
| < Content:
| |
| {
| |
| "data" : {
| |
| }
| |
| }
| |
|
| |
|
| == Get file metadata ==
| | Since session data is backed up by default continously by multiple nodes in the cluster, the steps described in [[ Session_Migration ]] to trigger session mirgration to other nodes explicitly is obsolete and no longer needed with the distributed session storage. |
|
| |
|
| Deprecated, available until API version 2. <br />
| | Normally, sessions in the distributed storages are not evicted automatically, but are only removed when they're also removed from the session handler, either due to a logout operation or when exceeding the long-term session lifetime as configured by ''com.openexchange.sessiond.sessionLongLifeTime'' in ''sessiond.properties''. Under certain circumstances, i.e. the session is no longer accessed by the client and the OX node hosting the session in it's long-life container being shutdown, the remove operation from the distributed storage might not be triggered. Therefore, additionaly a maximum idle time of map-entries can be configured for the distributed sessions map via |
| Additional metadata of synchronized files is made available via the <code>fileMetadata</code> request.
| |
|
| |
|
| PUT <code>/ajax/drive?action=fileMetata</code>
| | com.openexchange.hazelcast.configuration.map.maxIdleSeconds=640000 |
|
| |
|
| Parameters:
| | To avoid unnecessary eviction, the value should be higher than the configured ''com.openexchange.sessiond.sessionLongLifeTime'' in ''sessiond.properties''. |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>path</code> - The path to the synchronized folder, relative to the root folder.
| |
| * <code>columns</code> - A comma-separated list of columns to return. Each column is specified by a numeric column identifier. Column identifiers for file metadata are defined in [[#File Metadata]].
| |
|
| |
|
| Request Body:<br />
| | == Distributed Indexing Jobs == |
| A JSON array containing the file versions to get the metadata for. Each object in the array should be sent as [[#File Version | File Versions]], and needs to be present in the referenced path.
| |
|
| |
|
| Response:<br />
| | Groupware data is indexed in the background to yield faster search results. See the article on the [[Indexing Bundle]] for more. |
| A JSON array containing the file metadata in the order of the requested file versions. Each array element describes one file metadata and is itself an array. The elements of each array contain the information specified by the corresponding identifiers in the columns parameter.
| |
|
| |
|
| {| id="FileMetadataDeprecated" cellspacing="0" border="1"
| | == Remote Cache Invalidation == |
| |+ align="bottom" | File Metadata (deprecated)
| |
| ! ID !! Name !! Type !! Value
| |
| |-
| |
| | name || String || The name of the file version.
| |
| |-
| |
| | 4 || created || Timestamp || The file's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | 5 || modified || Timestamp || The file's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | 702 || name || String || The name of the file, including it's extension, e.g. <code>test.doc</code>.
| |
| |-
| |
| | 703 || contentType || String || The file's content type, e.g. "image/png".
| |
| |-
| |
| | 708 || checksum || String || The MD5 hash of the file, expressed as a lowercase hexadecimal number string, 32 characters long, e.g. <code>f8cacac95379527cd4fa15f0cb782a09</code>.
| |
| |-
| |
| | 750 || previewLink || String || A direct link to a medium-sized preview image of the file if available.
| |
| |-
| |
| | 751 || directLinkFragments || String | The fragments part of the direct link that can be used in combination with the [[http://oxpedia.org/index.php?title=HTTP_API#Token_Login_.28since_7.0.1.29 |token login]] method to jump directly to the detail view of the file in the web interface, bypassing the need to login manually.
| |
| |-
| |
| | 752 || directLink || String || A direct link to the detail view of the file in the web interface.
| |
| |-
| |
| | 753 || thumbnailLink || String || A direct link to a small thumbnail image of the file if available.
| |
| |}
| |
|
| |
|
| Example:
| | For faster access, groupware data is held in different caches by the server. Formerly, the caches utilized the TCP Lateral Auxiliary Cache plug in (LTCP) for the underlying JCS caches to broadcast updates and removals to caches on other OX nodes in the cluster. This could potentially lead to problems when remote invalidation was not working reliably due to network discovery problems. As an alternative, remote cache invalidation can also be performed using reliable publish/subscribe events built up on Hazelcast topics. This can be configured in the ''cache.properties'' configuration file, where the 'eventInvalidation' property can either be set to 'false' for the legacy behavior or 'true' for the new mechanism: |
| ==> PUT http://192.168.32.191/ajax/drive?action=fileMetadata&root=97974&path=%2f&columns=702%2c708%2c752%2c750%2c753&session=43aca91a80de42559ff0c2493dd973d0
| |
| > Content:
| |
| [
| |
| {
| |
| "name" : "image.jpg",
| |
| "checksum" : "2b04df3ecc1d94afddff082d139c6f15"
| |
| }, {
| |
| "name" : "song.mp3",
| |
| "checksum" : "5a9a91184e611dae3fed162b8787ce5f"
| |
| }, {
| |
| "name" : "test1.txt",
| |
| "checksum" : "7e36f409a042f06ecb88606a97a88c8f"
| |
| }, {
| |
| "name" : "test3.txt",
| |
| "checksum" : "703bc9aabff33faf07cf121dcda12ec8"
| |
| }
| |
| ]
| |
|
| |
| <== HTTP 200 OK (6.0004 ms elapsed, 140 bytes received)
| |
| < Content:
| |
| [
| |
| ["image.jpg", "2b04df3ecc1d94afddff082d139c6f15", "https://192.168.32.191/ox6/index.html#m=infostore&f=97974&i=179629", "https://192.168.32.191/ajax/files?action=document&folder=97974&id=179629&version=1&delivery=download&scaleType=contain&width=128&height=90", "m=infostore&f=97974&i=179629"],
| |
| ["song.mp3", "5a9a91184e611dae3fed162b8787ce5f", "https://192.168.32.191/ox6/index.html#m=infostore&f=97974&i=179630", "https://192.168.32.191/ajax/image/file/mp3Cover?folder=97974&id=179630&version=1&delivery=download&scaleType=contain&width=128&height=90", "m=infostore&f=97974&i=179630"],
| |
| ["test1.txt", "7e36f409a042f06ecb88606a97a88c8f", "https://192.168.32.191/ox6/index.html#m=infostore&f=97974&i=179626", null, "m=infostore&f=97974&i=179626"],
| |
| ["test3.txt", "703bc9aabff33faf07cf121dcda12ec8", "https://192.168.32.191/ox6/index.html#m=infostore&f=97974&i=179624", null, "m=infostore&f=97974&i=179624"]
| |
| ]
| |
| | |
| == Get a direct link for a folder/a file into appsuite ==
| |
| | |
| Generate a direct link into appsuite UI for a synchronized file/a synchronized folder and a token for token-based login.
| |
| | |
| POST <code>/ajax/drive?action=jump</code>
| |
| | |
| Parameters:
| |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>root</code> - The ID of the referenced root folder on the server.
| |
| * <code>path</code> - The path to the synchronized folder, relative to the root folder.
| |
| * <code>name</code> - The name of the file in the synchronized folder given in <code>path</code>-parameter. Optional
| |
| * <code>method</code> - [[#Methods | Methods]]
| |
| * <code>authId</code> - Identifier for tracing every single login request passed between different systems in a cluster. The value should be some token that is unique for every login request. This parameter must be given as URL parameter and not inside the body of the POST request.
| |
| * <code>clientToken</code> - Client side identifier for accessing the session later. The value should be some token that is unique for every login request.
| |
| | |
| Methods:<br />
| |
| * <code>edit</code>: Open the file in appsuite editor or in text/spreadsheet (if available).
| |
| * <code>permissions</code>: Open the file's/folder's change-permission dialog.
| |
| * <code>version_history</code>: Open the file's version history summary.
| |
| * <code>preview</code>: Open the file's/folder's preview.
| |
| | |
| Response:<br />
| |
| A JSON array containing the direct link to the file/folder including a server token for token based login.
| |
| | |
| Example:
| |
| ==> POST http://localhost/ajax/drive?action=jump&session=48a289898ad949faaa46c04e7fb422f5&root=9547&path=/path/to/file&name=file_to_edit.txt&method=edit&authId=41763584-8460-11e4-b116-123b93f75dba
| |
| > Content: clientToken=47d74b1c-81df-11e4-b116-123b93f75cba
| |
|
| |
| <== HTTP 200 OK
| |
| < Content:
| |
| {
| |
| "data": {
| |
| "redirectUrl": "http://localhost/appsuite#app=io.ox/editor&folder=273264&id=273264/307438&serverToken=7b90972628e34e89bb9a3946d1372c68"
| |
| }
| |
| }
| |
|
| |
|
| == Use direct link and token with token-based login == | | com.openexchange.caching.jcs.eventInvalidation=true |
|
| |
|
| Login to appsuite UI with token-based login via the link created with [[#Get a direct link for a folder/a file into appsuite | Get a direct link for a folder/a file into appsuite]].
| | All nodes participating in the cluster should be configured equally. |
|
| |
|
| GET <code>[direct link]</code>
| | Internally, if ''com.openexchange.caching.jcs.eventInvalidation'' is set to ''true'', LTCP is disabled in JCS caches. Instead, an internal mechanism based on distributed Hazelcast event topics is used to invalidate data throughout all nodes in the cluster after local update- and remove-operations. Put-operations aren't propagated (and haven't been with LTCP either), since all data put into caches can be locally loaded/evaluated at each node from the persistent storage layer. |
|
| |
|
| Parameters:
| | Using Hazelcast-based cache invalidation also makes further configuration of the JCS auxiliaries obsolete in the ''cache.ccf'' configuration file. In that case, all ''jcs.auxiliary.LTCP.*'' configuration settings are virtually ignored. However, it's still required to mark caches that require cluster-wide invalidation via ''jcs.region.<cache_name>=LTCP'', just as before. So basically, when using the new default setting ''com.openexchange.caching.jcs.eventInvalidation=true'', it's recommended to just use the stock ''cache.ccf'' file, since no further LTCP configuration is required. |
| * <code>clientToken</code> – Client side identifier for accessing the session. The value must be the same as in [[#Get a direct link for a folder/a file into appsuite | Get a direct link for a folder/a file into appsuite]]. | |
|
| |
|
| Example:
| |
| ==> GET http://localhost/appsuite#app=io.ox/editor&folder=273264&id=273264/307438&serverToken=7b90972628e34e89bb9a3946d1372c68&clientToken=47d74b1c-81df-11e4-b116-123b93f75cba
| |
| | | |
| <== HTTP 200 OK
| | = Adminstration / Troubleshooting = |
| | |
| == Get synchronizable Folders ==
| |
| | |
| Available since API version 4. <br />
| |
| | |
| Allows getting a list of folders that are available on the server for synchronization. This request should be used to build up a folder tree and let the user select the root synchronization folder(s).
| |
| | |
| GET <code>/ajax/drive?action=subfolders</code>
| |
| | |
| Parameters:
| |
| * <code>session</code> - A session ID previously obtained from the login module.
| |
| * <code>parent</code> - The ID of the parent folder to get the subfolders for as read from a previously fetched directory metadata object. Optional; if not set, the root available root folders are returned.
| |
| | |
| Response:<br />
| |
| A JSON array holding metadata information for all subfolders as defined in [[#Directory Metadata | Directory Metadata]], with the <code>files</code> array being left out.
| |
| | |
| Example:
| |
| ==> GET http://192.168.32.191/ajax/drive?action=subfolders&session=35cb8c2d1423480692f0d5053d14ba52
| |
|
| |
| <== HTTP 200 OK (241.0252 ms elapsed, 966 bytes received)
| |
| < Content:
| |
| {
| |
| "data": [{
| |
| "id": "com.openexchange.file.storage.googledrive://1/",
| |
| "name": "Google Drive",
| |
| "path": "/Google Drive",
| |
| "has_subfolders": true,
| |
| "own_rights": 403710016,
| |
| "permissions": [{
| |
| "bits": 403710016,
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| }],
| |
| "jump": ["permissions"]
| |
| },
| |
| {
| |
| "id": "10",
| |
| "name": "Freigegebene Dateien",
| |
| "path": "/Freigegebene Dateien",
| |
| "created": 1224493261628,
| |
| "modified": 1417164170136,
| |
| "has_subfolders": true,
| |
| "own_rights": 1,
| |
| "permissions": [{
| |
| "bits": 1,
| |
| "group": true,
| |
| "entity": 0,
| |
| "display_name": "All users",
| |
| "guest": false
| |
| },
| |
| {
| |
| "bits": 1,
| |
| "group": true,
| |
| "entity": 2147483647,
| |
| "display_name": "Guests",
| |
| "guest": false
| |
| }],
| |
| "jump": ["permissions"],
| |
| "shared": true
| |
| },
| |
| {
| |
| "id": "15",
| |
| "name": "Öffentliche Dateien",
| |
| "path": "/Öffentliche Dateien",
| |
| "created": 1224493261628,
| |
| "modified": 1418383637250,
| |
| "has_subfolders": true,
| |
| "own_rights": 403709956,
| |
| "permissions": [{
| |
| "bits": 403709956,
| |
| "group": true,
| |
| "entity": 0,
| |
| "display_name": "All users",
| |
| "guest": false
| |
| },
| |
| {
| |
| "bits": 1,
| |
| "group": true,
| |
| "entity": 2147483647,
| |
| "display_name": "Guests",
| |
| "guest": false
| |
| }],
| |
| "jump": ["permissions"],
| |
| "shared": true
| |
| },
| |
| {
| |
| "id": "com.openexchange.file.storage.dropbox://1/",
| |
| "name": "Dropbox",
| |
| "path": "/Dropbox",
| |
| "has_subfolders": true,
| |
| "own_rights": 403710016,
| |
| "permissions": [{
| |
| "bits": 403710016,
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| }],
| |
| "jump": ["permissions"]
| |
| },
| |
| {
| |
| "id": "9542",
| |
| "name": "Meine Dateien",
| |
| "path": "/Meine Dateien",
| |
| "created": 1320230546147,
| |
| "modified": 1426764458823,
| |
| "default_folder": true,
| |
| "has_subfolders": true,
| |
| "own_rights": 403710016,
| |
| "permissions": [{
| |
| "bits": 403710016,
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| }],
| |
| "jump": ["permissions"]
| |
| }]
| |
| }
| |
| | |
| = File- and Directory Name Restrictions =
| |
| | |
| Regarding the case sensitivity of file and directory names, OX Drive works in a case-insensitive, but case-preserving way. That means that there cannot be two files with an equal name ignoring case in the same directory, but it's still possible to synchronize the names in a case-sensitive manner, as well as it's possible to change only the case of file- and directory names.
| |
| | |
| The same applies to equally named files and directories on the same level in the folder hierarchy, i.e. it's not possible to create a new file in a directory where an equally (ignoring case) named subdirectory already exists and vice versa.
| |
| | |
| There is a similar restriction regarding file and directory names in the same directory having different unicode normalization forms, yet the same textual representation. OX Drive requires uniqueness regarding this textual representaion of potentially different encoded unicode strings. So, in case the client tries to synchronize two textually equal files or directories, he is instructed to put one of them into quarantine. Internally the server performs an equals-check of the "NFC" normalization forms of the strings, i.e. an unicode string is normalized using full canonical decomposition, followed by the replacement of sequences with their primary composites, if possible. Details regarding unicode normalization can be found at http://www.unicode.org/reports/tr15/tr15-23.html .
| |
| | |
| == Invalid and ignored Filenames ==
| |
| | |
| There are some filenames that are invalid or ignored and therefore not synchronized. This means that files with these names should not be taken into account when sending the directory contents to the server, or when calculating the directory checksum (see below). The following list describes when a filename is considered invalid:
| |
| * If it contains one or of the following reserved characters:
| |
| ** <code><</code> (less than),
| |
| ** <code>></code> (greater than)
| |
| ** <code>:</code> (colon)
| |
| ** <code>"</code> (double quote)
| |
| ** <code>/</code> (forward slash)
| |
| ** <code>\</code> (backslash)
| |
| ** <code>|</code> (vertical bar or pipe)
| |
| ** <code>?</code> (question mark)
| |
| ** <code>*</code> (asterisk)
| |
| ** Characters whose integer representations are in the range from 0 through 31
| |
| * The last character is a <code>.</code> (dot) or <code>' '</code> (space)
| |
| * It's case-invariant name without an optional extension matches one of the reserved names <code>CON</code>, <code>PRN</code>, <code>AUX</code>, <code>NUL</code>, <code>COM1</code>, <code>COM2</code>, <code>COM3</code>, <code>COM4</code>, <code>COM5</code>, <code>COM6</code>, <code>COM7</code>, <code>COM8</code>, <code>COM9</code>, <code>LPT1</code>, <code>LPT2</code>, <code>LPT3</code>, <code>LPT4</code>, <code>LPT5</code>, <code>LPT6</code>, <code>LPT7</code>, <code>LPT8</code>, or <code>LPT9</code>
| |
| * It consists solely of whitespace characters
| |
| | |
| The following list gives an overview about the ignored filenames:
| |
| * <code>desktop.ini</code>
| |
| * <code>Thumbs.db</code>
| |
| * <code>.DS_Store</code>
| |
| * <code>icon\r</code>
| |
| * Any filename ending with <code>.drivepart</code>
| |
| * Any filename starting with <code>.msngr_hstr_data_</code> and ending with <code>.log</code>
| |
| | |
| Nevertheless, if the client still insists to send a file version with an invalid or ignored filename, the file creation on the server is refused with a corresponding <code>error</code> action (see below).
| |
|
| |
|
| == Invalid and ignored Directory Names == | | == Hazelcast Configuration == |
|
| |
|
| There are also similar restrictions regarding invalid directory names. Any try to include them in the list of directory versions will be responded with a corresponding error action for the directory version. The following list describes when a path is considered invalid:
| | The underlying Hazelcast library can be configured using the file ''hazelcast.properties''. |
| * If it contains one or of the following reserved characters:
| |
| ** <code><</code> (less than),
| |
| ** <code>></code> (greater than)
| |
| ** <code>:</code> (colon)
| |
| ** <code>"</code> (double quote)
| |
| ** <code>\</code> (backslash)
| |
| ** <code>|</code> (vertical bar or pipe)
| |
| ** <code>?</code> (question mark)
| |
| ** <code>*</code> (asterisk)
| |
| ** Characters whose integer representations are in the range from 0 through 31
| |
| * The last character of any subpath (i.e. the last part of the whole path or the part preceding the spearator character <code>/</code>) is a <code>.</code> (dot) or <code>' '</code> (space)
| |
| * It consists solely of whitespace characters
| |
| * It not equals the root path <code>/</code>, but ends with a <code>/</code> (forward slash) character
| |
| * It contains two or more consecutive <code>/</code> (forward slash) characters
| |
|
| |
|
| The following list gives an overview about the ignored directory names:
| | '''Important''':<br> |
| * <code>/.drive</code>
| | By default property ''com.openexchange.hazelcast.network.interfaces'' is set to ''127.0.0.1''; meaning Hazelcast listens only to loop-back device. To build a cluster among remote nodes the appropriate network interface needs to be configured there. Leaving that property empty lets Hazelcast listen to all available network interfaces. |
| * Any directory whose path ends with <code>/.msngr_hstr_data</code>
| |
|
| |
|
| == Length Restrictions ==
| | The Hazelcast JMX MBean can be enabled or disabled with the property ''com.openexchange.hazelcast.jmx''. The properties ''com.openexchange.hazelcast.mergeFirstRunDelay'' and ''com.openexchange.hazelcast.mergeRunDelay'' control the run intervals of the so-called ''Split Brain Handler'' of Hazelcast that initiates the cluster join process when a new node is started. More details can be found at http://www.hazelcast.com/docs/2.5/manual/single_html/#NetworkPartitioning. |
|
| |
|
| The maximum allowed length for path segments, i.e. the parts between forawrd slashes (</code>/</code>) in directory and filenames, is restricted to 255 characters. Synchronizing a file or directory version that contains path segments longer than this limit leads to those versions being put into quarantine. | | The port ranges used by Hazelcast for incoming and outgoing connections can be controlled via the configuration parameters ''com.openexchange.hazelcast.networkConfig.port'', ''com.openexchange.hazelcast.networkConfig.portAutoIncrement'' and ''com.openexchange.hazelcast.networkConfig.outboundPortDefinitions''. |
|
| |
|
| = Client side filtering = | | == Commandline Tool == |
|
| |
|
| Client-side filtering is available since API version 2. <br />
| | To print out statistics about the cluster and the distributed data, the ''showruntimestats'' commandline tool can be executed witht the ''clusterstats'' ('c') argument. This provides an overview about the runtime cluster configuration of the node, other members in the cluster and distributed data structures. |
|
| |
|
| OX Drive clients may define a user- and/or application-defined list of file- and directory name exclusions. Those exclusion filters are then taken into account during synchronization, i.e. files and directories matching a defined exclusion pattern are ignored when comparing the list of server-, client- and original versions. Also, the file exclusion lists are considered for the calculation of aggergated directory checksums.
| | == JMX == |
|
| |
|
| The exclusion filters may be set, changed or unset at any time during synchronization, there are no additional requests needed to set them up. Instead, the list of excluded files and directories is simply sent along with each <code>syncFolders</code>, <code>syncFiles</code> and <code>download</code> request. The following tables show the JSON representation of file- and directory patterns that are used to build up the exlcusion lists:
| | In the Open-Xchange server Java process, the MBean ''com.hazelcast'' can be used to monitor and manage different aspects of the underlying Hazelcast cluster. The ''com.hazelcast'' MBean provides detailed information about the cluster configuration and distributed data structures. |
|
| |
|
| == Directory pattern == | | == Hazelcast Errors == |
|
| |
|
| A directory pattern is defined by a pattern string and further attributes.
| | When experiencing hazelcast related errors in the logfiles, most likely different versions of the packages are installed, leading to different message formats that can't be understood by nodes using another version. Examples for such errors are exceptions in hazelcast components regarding (de)serialization or other message processing. |
| | This may happen when performing a consecutive update of all nodes in the cluster, where temporarily nodes with a heterogeneous setup try to communicate with each other. If the errors don't disappear after all nodes in the cluster have been update to the same package versions, it might be necessary to shutdown the cluster completely, so that all distributed data is cleared. |
|
| |
|
| {| id="DirectoryPattern" cellspacing="0" border="1"
| | == Cluster Discovery Errors == |
| |+ align="bottom" | Directory Pattern
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | type || String || The pattern type, currently one of <code>exact</code> or <code>glob</code>.
| |
| |-
| |
| | path || String || The path pattern, in a format depending on the pattern type.
| |
| |-
| |
| | caseSensitive || Boolean | Optional flag to enable case-sensitive matching, defaults to <code>false</code>
| |
| |}
| |
|
| |
|
| == File pattern ==
| | * If the started OX nodes don't form a cluster, please double-check your configuration in ''hazelcast.properties'' |
| | * It's important to have the same cluster name defined in ''hazelcast.properties'' throughout all nodes in the cluster |
| | * Especially when using multicast cluster discovery, it might take some time until the cluster is formed |
| | * When using ''static'' cluster discovery, at least one other node in the cluster has to be configured in ''com.openexchange.hazelcast.network.join.static.nodes'' to allow joining, however, it's recommended to list all nodes in the cluster here |
|
| |
|
| A file pattern is defined by pattern strings for the filename and path, as well as further attributes.
| | == Disable Cluster Features == |
|
| |
|
| {| id="FilePattern" cellspacing="0" border="1"
| | The Hazelcast based clustering features can be disabled with the following property changes: |
| |+ align="bottom" | File Pattern
| | * Disable cluster discovery by setting ''com.openexchange.hazelcast.network.join'' to ''empty'' in ''hazelcast.properties'' |
| ! Name !! Type !! Value
| | * Disable Hazelcast by setting ''com.openexchange.hazelcast.enabled'' to false in ''hazelcast.properties'' |
| |-
| | * Disable message based cache event invalidation by setting ''com.openexchange.caching.jcs.eventInvalidation'' to ''false'' in ''cache.properties'' |
| | type || String || The pattern type, currently one of <code>exact</code> or <code>glob</code>.
| |
| |-
| |
| | path || String || The path pattern, in a format depending on the pattern type.
| |
| |-
| |
| | name || String || The filename pattern, in a format depending on the pattern type.
| |
| |-
| |
| | caseSensitive || Boolean | Optional flag to enable case-sensitive matching, defaults to <code>false</code>
| |
| |}
| |
|
| |
|
| == Pattern types == | | == Update from 6.22.1 to version 6.22.2 and above == |
|
| |
|
| A pattern currently may be defined in two formats: <code>exact</code> or <code>glob</code>.
| | As hazelcast will be used by default for the distribution of sessions starting 6.22.2 you have to adjust hazelcast according to our old cache configuration. First of all it's important that you install the open-xchange-sessionstorage-hazelcast package. This package will add the binding between hazelcast and the internal session management. Next you have to set a cluster name to the cluster.properties file (see [[#Cluster Discovery Errors]]). Furthermore you will have to add one of the two discovery modes mentioned in [[#Cluster Discovery]]. |
|
| |
|
| * <code>exact</code> <br /> An exact pattern, matching the file- or directory version literally. For example, to exclude the file <code>Backup.pst</code> in the subfolder <code>Mail</code> below the root synchronization folder, an <code>exact</code> file pattern would look like: <code>{"path":"/Mail","name":"Backup.pst","type":"exact"}</code>, or, an <code>exact</code> directory pattern for the directory <code>/Archive</code> would be represented as <code>{"path":"/Archive","type":"exact"}</code>.
| |
| * <code>glob</code> <br /> A simple pattern allowing to use the common wildcards <code>*</code> and <code>?</code> to match file- and directory versions. For example, to exclude all files ending with <code>.tmp</code> across all directories, the <code>glob</code> file pattern could be defined as <code>{"path":"*","name":"*.tmp","type":"glob"}</code>, or, to exclude the directory <code>/Project/.git</code> and all its subdirectories recursively, this would be expressed using a combination of the following two directory patterns: <code>[{"path":"/Project/.git","type":"exact"},{"path":"/Project/.git*","type":"glob"}]</code>.
| |
|
| |
|
| == Further considerations == | | = Updating a Cluster = |
|
| |
|
| * It's possible to exclude a (parent) directory with an appropriate pattern, while still subfolders below that directory being synchronized. This usually results in the excluded directory being created ob both client- and server side, but no file contents within the excluded directory being exchanged. If subfolders should be excluded, too, a wildcard should be used in the pattern to match any subdirectories.
| | Running a cluster means built-in failover on the one hand, but might require some attention when it comes to the point of upgrading the services on all nodes in the cluster. This chapter gives an overview about general concepts and hints for silent updates of the cluster. |
| * If the client tries to synchronize a file- or directory version that is ignored, i.e. a version that would match any of the provided exclusion filters, the server behaves similarly to the handling of invalid and ignored file- and directory names (see above), i.e. the client would be instructed to put those versions into quarantine.
| |
| * For the calculation of directory checksums, it's important that the server and client perform exactly the same matching for ignored filenames: A <code>*</code> character matches zero or more characters, a <code>?</code> character matches exactly one character. All other characters are matched literally. Advanced glob flavors like braces to define subpattern alternatives or square brackets for character sets are not used.
| |
| * Client-side filtering is available with API version 2. The API version that is supported by the server is included in the response of the [[#Get Settings | Settings]] request.
| |
| * Whenever there are active exclusion filters, the <code>syncFolders</code> request should contain all of both directory and file exclusion filter lists. For the <code>syncFiles</code> request, it's sufficient to include the list of file exclusions.
| |
|
| |
|
| | == Limitations == |
|
| |
|
| = Metadata Synchronization =
| | While in most cases a seamless, rolling upgrade of all nodes in the cluster is possible, there may be situations where nodes running a newer version of the Open-Xchange Server are not able to communicate with older nodes in the cluster, i.e. can't access distributed data or consume incompatible event notifications - especially, when the underlying Hazelcast library is part of the update, which does not support this scenario at the moment. In such cases, the release notes will contain corresponding information, so please have a look there before applying an update. |
|
| |
|
| The synchronization of metadata is available since API version 3. <br />
| | Additionally, there may always be some kind of race conditions during an update, i.e. client requests that can't be completed successfully or internal events not being deliverd to all nodes in the cluster. That's why the following information should only serve as a best-practices guide to minimize the impact of upgrades to the user experience. |
|
| |
|
| == Introduction == | | == Upgrading a single Node == |
|
| |
|
| Previously, only the "raw" folders and files were synchronized between server and clients. While this is sufficient for basic synchronization, there are cases where the clients could benefit from additional data - "metadata" - that is already available on the server. For example, clients could display directories that have been shared or published to other people in a different way. Or, clients could consider folder permissions directly in case the user is performing a local change that would be rejected by the server in the next synchronization cycle anyway.
| | Upgrading all nodes in the cluster should usually be done sequentially, i.o.w. one node after the other. This means that during the upgrade of one node, the node is temporarily disconnected from the other nodes in the cluster, and will join the cluster again after the update is completed. From the backend perspective, this is as easy as stopping the open-xchange service. other nodes in the cluster will recognize the disconnected node and start to repartition the shared cluster data automatically. But wait a minute - doing so would potentially lead to the webserver not registering the node being stopped immediately, resulting in temporary errors for currently logged in users until they are routed to another machine in the cluster. That's why it's good practice to tell the webserver's load balancer that the node should no longer fulfill incoming requests. The Apache Balancer Manager is an excellent tool for this ([http://httpd.apache.org/docs/2.2/mod/mod_status.html module ''mod_status'']). Look at the screen shot. Every node can be put into a disabled mode. Further requests will the redirected to other nodes in the cluster: |
|
| |
|
| To supply the clients with those additional information without any influence on the existing synchronization protocol (!), <code>.drive-meta</code> files are introduced for each synchronized directory. Regarding synchronization, such files are treated like any other ordinary file. Especially, those files are taken into account when it comes to directory checksum calculation. Doing so, metadata updates result in a changed <code>.drive-meta</code> file, which in turn causes the parent directory checksum to change, hence synchronization is triggered.
| |
|
| |
|
| However, some special handling applies for those files:
| | [[Image:balancer_manager.jpg]] |
|
| |
|
| * Clients are not allowed to change metadata, so modifications of metadata files or the deletion of them is rejected. Recovery is done via the protocol here, i.e. the client is instructed to re-download the file.
| |
| * <code>.drive-meta</code> files are actually not stored physically on the file storage backend, but created on the fly based on the actual metadata of the directory.
| |
| * Client applications may either store such files on the client file system, or evaluate and store the contained metadata information in a local database for later retrieval. If the file is not saved physically on the client (which is actually recommended), the client is responsible to consider the metadata file in a virtual way and include it's checksum for the directory checksum calculation - similar to the server's internal handling.
| |
|
| |
|
| == Metadata format ==
| | Afterwards, the open-xchange service on the disabled node can be stopped by executing: |
|
| |
|
| The metadata in <code>.drive-meta</code> files is serialized in JSON format to allow easy processing at the clients. The following shows an example of the contents:
| | $ /etc/init.d/open-xchange stop |
| { | |
| "path": "/",
| |
| "created": 1418024049629,
| |
| "modified": 1418024189166,
| |
| "own_rights": 403710016,
| |
| "permissions": [{
| |
| "bits": 403710016,
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| }],
| |
| "jump": ["permissions"],
| |
| "files": [{
| |
| "name": "Koala.jpg",
| |
| "created": 1418024190565,
| |
| "modified": 1418026995663,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "preview": "http://192.168.32.191/ajax/files?action=document&folder=268931&id=268931/297620&version=1&delivery=download&scaleType=contain&width=800&height=800&rotate=true",
| |
| "thumbnail": "http://192.168.32.191/ajax/files?action=document&folder=268931&id=268931/297620&version=1&delivery=download&scaleType=contain&width=100&height=100&rotate=true",
| |
| "object_permissions": [{
| |
| "bits": 1,
| |
| "group": false,
| |
| "entity": 10,
| |
| "display_name": "Jan Ot/to Finsel",
| |
| "email_address": "jan.finsel@premium",
| |
| "guest": false
| |
| },
| |
| {
| |
| "bits": 1,
| |
| "group": false,
| |
| "entity": 8338,
| |
| "email_address": "horst@example.com",
| |
| "guest": true
| |
| }],
| |
| "shared": true,
| |
| "number_of_versions": 1,
| |
| "version": "1",
| |
| "jump": ["preview",
| |
| "permissions",
| |
| "version_history"]
| |
| },
| |
| {
| |
| "name": "test.txt",
| |
| "created": 1418024198520,
| |
| "modified": 1418027394897,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "preview": "http://192.168.32.191/ajax/files?action=document&format=preview_image&folder=268931&id=268931/297621&version=6&delivery=download&scaleType=contain&width=800&height=800",
| |
| "thumbnail": "http://192.168.32.191/ajax/files?action=document&format=preview_image&folder=268931&id=268931/297621&version=6&delivery=download&scaleType=contain&width=100&height=100",
| |
| "locked": true,
| |
| "number_of_versions": 4,
| |
| "version": "6",
| |
| "version_comment": "Uploaded with OX Drive (TestDrive)",
| |
| "versions": [{
| |
| "name": "test.txt",
| |
| "file_size": 23,
| |
| "created": 1418024198520,
| |
| "modified": 1418024202878,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "version": "1",
| |
| "version_comment": "Uploaded with OX Drive (TestDrive)"
| |
| },
| |
| {
| |
| "name": "test.txt",
| |
| "file_size": 54,
| |
| "created": 1418024234782,
| |
| "modified": 1418024231522,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "version": "2",
| |
| "version_comment": "Uploaded with OX Drive (TestDrive)"
| |
| },
| |
| {
| |
| "name": "test.txt",
| |
| "file_size": 120,
| |
| "created": 1418027349026,
| |
| "modified": 1418027355957,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "version": "5"
| |
| },
| |
| {
| |
| "name": "test.txt",
| |
| "file_size": 127,
| |
| "created": 1418027370051,
| |
| "modified": 1418027366945,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "version": "6",
| |
| "version_comment": "Uploaded with OX Drive (TestDrive)"
| |
| }],
| |
| "jump": ["preview",
| |
| "edit",
| |
| "permissions",
| |
| "version_history"]
| |
| },
| |
| {
| |
| "name": "Kalimba.mp3",
| |
| "created": 1418026529047,
| |
| "modified": 1247549551659,
| |
| "created_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "modified_by": {
| |
| "group": false,
| |
| "entity": 182,
| |
| "display_name": "Mander, Jens",
| |
| "email_address": "jens.mander@example.com",
| |
| "guest": false
| |
| },
| |
| "preview": "http://192.168.32.191/ajax/image/file/mp3Cover?folder=268931&id=268931/297623&version=1&delivery=download&scaleType=contain&width=800&height=800",
| |
| "thumbnail": "http://192.168.32.191/ajax/image/file/mp3Cover?folder=268931&id=268931/297623&version=1&delivery=download&scaleType=contain&width=100&height=100",
| |
| "number_of_versions": 1,
| |
| "version": "1",
| |
| "version_comment": "Uploaded with OX Drive (TestDrive)",
| |
| "jump": ["preview",
| |
| "permissions",
| |
| "version_history"]
| |
| }]
| |
| }
| |
|
| |
|
| The following objects describe the JSON structure of the metadata for a directory:
| | or |
|
| |
|
| {| id="DirectoryMetadata" cellspacing="0" border="1"
| | $ service open-xchange stop |
| |+ align="bottom" | Directory Metadata
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | id || String || The server-side unique identifier of the directory.
| |
| |-
| |
| | name || String || The display name of the directory.
| |
| |-
| |
| | path || String || The path of the directory the metadata belongs to.
| |
| |-
| |
| | created || Timestamp || The folder's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | modified || Timestamp || The folder's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | own_rights || Number|| Folder permissions which apply to the current user, as described in [[http://oxpedia.org/index.php?title=HTTP_API#PermissionFlags | permission flags]].
| |
| |-
| |
| | permissions || Array || All folder permissions, each element is an object as described in [[#Folder Permission | Folder Permission]].
| |
| |-
| |
| | default_folder || Boolean || <code>true</code> if the folder is a default folder, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | has_subfolders || Boolean || <code>true</code> if the folder (potentially) has subfolders, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | shared || Boolean || <code>true</code> if the folder is shared, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | type || Number || The special folder type, or not set, if not available.
| |
| |-
| |
| | jump || Array || An array containing the names of possible <code>jump</code> methods to use for the folder.
| |
| |-
| |
| | files || Array || Metadata for the contained files, each element is an object as described in [[#File Metadata | File Metadata]].
| |
| |}
| |
|
| |
|
| | Now, the node is effectively in maintenance mode and any updates can take place. One could now verify the changed cluster infrastructure by accessing the Hazelcast MBeans either via JMX or the ''showruntimestats -c'' commandline tool (see above for details). There, the shut down node should no longer appear in the 'Member' section (com.hazelcast:type=Member). |
|
| |
|
| {| id="FileMetadata" cellspacing="0" border="1"
| | When all upgrades are processed, the node open-xchange service can be started again by executing: |
| |+ align="bottom" | File Metadata
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | name || String || The name of the file the metadata belongs to.
| |
| |-
| |
| | created || Timestamp || The file's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | modified || Timestamp || The file's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | created_by || Object || Information about the file's creator as described in [[#Entity Information | Entity Information]].
| |
| |-
| |
| | modified_by || Object || Information about the file's last editor as described in [[#Entity Information | Entity information]].
| |
| |-
| |
| | preview || String || A URL to a preview image for the file.
| |
| |-
| |
| | thumbnail || String || A URL to a thumbnail image for the file.
| |
| |-
| |
| | object_permissions || Array | All file permissions, each element is an object as described in [[#Object Permission | Object Permission]].
| |
| |-
| |
| | shared || Boolean || <code>true</code> if the file is shared, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | locked || Boolean || <code>true</code> if the file is locked, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | jump || Array || An array containing the names of possible <code>jump</code> methods to use for the file.
| |
| |-
| |
| | number_of_versions || Number | The number of all versions of the file.
| |
| |-
| |
| | version || String || The current version identifier (usually, but not necessarily a numerical value) of the file.
| |
| |-
| |
| | version_comment || String | An additional comment for the file version.
| |
| |-
| |
| | versions || Array || Metadata for all versions of the file, each element is an object as described in [[#File Version | File Version]].
| |
| |}
| |
|
| |
|
| {| id="EntityInformation" cellspacing="0" border="1"
| | $ /etc/init.d/open-xchange start |
| |+ align="bottom" | Entity Information
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | entity || Number || The unique identifier of the entity.
| |
| |-
| |
| | group || Boolean || <code>true</code> if the entity is a group, <code>false</code> or not set, if it is a single user or guest.
| |
| |-
| |
| | display_name || String || A display name for the entity if available.
| |
| |-
| |
| | email_address || String || An e-mail address for the entity if available.
| |
| |-
| |
| | group || Boolean || <code>true</code> if the entity is an external guest, <code>false</code> or not set, otherwise.
| |
| |}
| |
|
| |
|
| {| id="FolderPermission" cellspacing="0" border="1"
| | or |
| |+ align="bottom" | Folder Permission
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | entity || Number || The unique identifier of the entity.
| |
| |-
| |
| | group || Boolean || <code>true</code> if the entity is a group, <code>false</code> or not set, if it is a single user or guest.
| |
| |-
| |
| | display_name || String || A display name for the entity if available.
| |
| |-
| |
| | email_address || String || An e-mail address for the entity if available.
| |
| |-
| |
| | group || Boolean || <code>true</code> if the entity is an external guest, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | bits || Number|| Permission level, as described in [[http://oxpedia.org/index.php?title=HTTP_API#PermissionFlags | permission flags]].
| |
| |}
| |
|
| |
|
| {| id="ObjectPermission" cellspacing="0" border="1"
| | $ service open-xchange start |
| |+ align="bottom" | Object Permission
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | entity || Number || The unique identifier of the entity.
| |
| |-
| |
| | group || Boolean || <code>true</code> if the entity is a group, <code>false</code> or not set, if it is a single user or guest.
| |
| |-
| |
| | display_name || String || A display name for the entity if available.
| |
| |-
| |
| | email_address || String || An e-mail address for the entity if available.
| |
| |-
| |
| | group || Boolean || <code>true</code> if the entity is an external guest, <code>false</code> or not set, otherwise.
| |
| |-
| |
| | bits || Number|| Object permission level, as described in [[http://oxpedia.org/index.php?title=HTTP_API#ObjectPermissionFlags | permission flags]].
| |
| |}
| |
|
| |
|
| {| id="FileVersion" cellspacing="0" border="1"
| | As stated above, depending on the chosen cluster discovery mechanism, it might take some time until the node joins the cluster again. When using static cluster discovery, it will join the existing cluster usually directly during serivce startup, i.o.w. before other depending OSGi services are started. Otherwise, there might also be situations where the node cannot join the cluster directly, for example when there were no mDNS advertisments for other nodes in the cluster received yet. Then, it can take some additional time until the node finally joins the cluster. During startup of the node, you can observe the JMX console or the output of ''showruntimestats -c'' (com.hazelcast:type=Member) of another node in the cluster to verify when the node has joined. |
| |+ align="bottom" | File Version
| |
| ! Name !! Type !! Value
| |
| |-
| |
| | name || String || The name of the file version.
| |
| |-
| |
| | file_size || Number || The file size of the version in bytes.
| |
| |-
| |
| | created || Timestamp || The file version's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | modified || Timestamp || The file version's last modification time (always UTC, not translated into user time).
| |
| |-
| |
| | created_by || Object || Information about the file version's creator as described in [[#Entity Information | Entity Information]].
| |
| |-
| |
| | modified_by || Object || Information about the file version's last editor as described in [[#Entity Information | Entity information]].
| |
| |-
| |
| | version || String || The version identifier (usually, but not necessarily a numerical value) of the file version.
| |
| |-
| |
| | version_comment || String || An additional comment for the file version.
| |
| |}
| |
|
| |
|
| == Client-side implementation ==
| | After the node has joined, distributed data is re-partioned automatically, and the node is ready to server incoming requests again - so now the node can finally be enabled again in the load balancer configuration of the webserver. Afterwards, the next node in the cluster can be upgraded using the same procedure, until all nodes were processed. |
|
| |
|
| In order to make use of the metadata, clients should roughly implement the following:
| | == Other Considerations == |
| * Include the <code>apiVersion</code> parameter in each request, and set it to at least <code>3</code> in order to include <code>.drive-meta</code> during synchronization
| |
| * Evaluate <code>.drive-meta</code> files and store the information, as well as the file's checksums in a local database
| |
| * Include this file in the calculation of the parent directory checksum, just like an ordinary file in that directory
| |
| * Do something useful with the metadata information.
| |
|
| |
|
| == Additional notes ==
| | * It's always recommended to only upgrade one node after the other, always ensuring that the cluster has formed correctly between each shutdown/startup of a node. |
| | * Do not stop a node while running the runUpdate script or the associated update task. |
| | * During the time of such a rolling upgrade of all nodes, we have effectively heterogeneous software versions in the cluster, which potentially might lead to temporary inconsistencies. Therefore, all nodes in the cluster should be updated in one cycle (but still one after the other). |
| | * Following the above guideline, it's also possible to add or remove nodes dynamically to the cluster, not only when disconnecting a node temporary for updates. |
| | * In case of trouble, i.e. a node refuses to join the cluster again after restart, consult the logfiles first for any hints about what is causing the problem - both on the disconnected node, and also on other nodes in the network |
| | * If there are general incompatibilities between two revisions of the Open-Xchange Server that prevent an operation in a cluster (release notes), it's recommended to choose another name for the cluster in ''cluster.properties'' for the nodes with the new version. This will temporary lead to two separate clusters during the rolling upgrade, and finally the old cluster being shut down completely after the last node was updated to the new version. While distributed data can't be migrated from one server version to another in this scenario due to incompatibilities, the uptime of the system itself is not affected, since the nodes in the new cluster are able to serve new incoming requests directly. |
|
| |
|
| * The metadata synchronization via <code>.drive-meta</code> files embedded into the synchronization protocol obsoletes the previously used methods to receive metadata information ([[#Get file metadata]] and <code>columns</code> parameter in [[#Synchronize files in a folder]].
| |
| * Depending on the underlying file storage backend, the included metadata may vary, so each information should be treatened as optional.
| |
|
| |
|
| == Possible use cases ==
| | [[Category: AppSuite]] [[Category: Administration]] [[Category: Cluster]] |
| * For files where the <code>locked</code> property is <code>true</code>, display some kind of "lock" icon (-overlay) in the file list / explorer view
| |
| * For files or folders where the <code>shared</code> property is <code>true</code>, display some kind of "cloud" icon (-overlay) in the file list / explorer view
| |
| * For files or folders where the user is not allowed to perform an action with, don't offer such actions (e.g. if a file cannot be deleted or renamed by the user due to insufficient permissions, disable the corresponding options)
| |
| * Use the URLs in <code>preview</code> and <code>thumbnail</code> to get a preview image for the files
| |
| * Display the server creation / last modification timestamps of files and folders
| |
| * Embed a version history for files with multiple versions
| |
| * Show to which users a file or folder is currently shared
| |
| * Offer appropriate "jump" actions to the groupware web interface for more advanced options (e.g. to directly edit an .xlsx file in the spreadsheet application of the web interface, or to manage a folder's permission
| |
Running a cluster
Concepts
For inter-OX-communication over the network, multiple Open-Xchange servers can form a cluster. This brings different advantages regarding distribution and caching of volatile data, load balancing, scalability, fail-safety and robustness. Additionally, it provides the infrastructure for upcoming features of the Open-Xchange server.
The clustering capabilities of the Open-Xchange server are mainly built up on Hazelcast, an open source clustering and highly scalable data distribution platform for Java. The following article provides an overview about the current featureset and configuration options.
Requirements on HTTP routing
An OX cluster is always part of a larger picture. Usually there is front level loadbalancer as central HTTPS entry point to the platform. This loadbalancer optionally performs HTTPS termination and forwards HTTP(S) requests to webservers (the usual and only supported choice as of now is Apache). These webservers are performing HTTPS termination (if this is not happening on the loadbalancer) and serve static content, and (which is what is relevant for our discussion here) they forward dynamic requests to the OX backends.
A central requirement for the interaction of these components (loadbalancer, webservers, OX nodes) is that we have session stability based on the JSESSIONID cookie / jsessionid path component suffix. This means that our application sets a cookie named JSESSIONID which has a value like <large decimal number>.<route identifier>, e.g. "5661584529655240315.OX1". The route identifier here ("OX1" in this example) is taken by the OX node from a configuration setting from a config file and is specific to one OX node. HTTP routing must happen such that HTTP requests with a cookie with such a suffix always end up the corresponding OX node. There are furthermore specific cirumstances when passing this information via cookie is not possible. Then the JSESSIONID is transferred in a path component as "jsessionid=..." in the HTTP request. The routing mechanism needs to take that into account also.
There are mainly two options to implement this. If the Apache processes are running co-located on the same machines running the OX groupware processes, it is often desired to have the front level loadbalancer perform HTTP routing to the correct machines. If dedicated Apache nodes are employed, is is usually sufficient to have the front-level loadbalancer do HTTP routing to the Apache nodes in a round-robin fashion and perform routing to the correct OX nodes in the Apache nodes.
We provide sample configuration files to configure Apache (with mod_proxy_http) to perform HTTP routing correctly in our guides on OXpedia, e.g. AppSuite:Main_Page_AppSuite#quickinstall. Central elements are the directives "ProxySet stickysession=JSESSIONID|jsessionid scolonpathdelim=On" in conjunction with the "route=OX1" parameters to the BalancerMember lines in the Proxy definition. This is valid for Apache 2.2 as of Sep-2014.
How to configure a front level loadbalancer to perform HTTP equivalent HTTP routing is dependent on the specific loadbalancer implementation. If Apache is used as front level loadbalancer, the same configuration as discussed in the previous section can be employed. As of time of writing this text (Sep 2014), the alternative choices are thin. F5 BigIP is reported to be able to implement "jsessionid based persistence using iRules". nginx has the functionality in their commercial "nginx plus" product. (Both of these options have not been tested by OX.) Other loadbalancers with this functionality are not known to us.
If the front level loadbalancer is not capable of performing correct HTTP routing, is is required to configure correct HTTP routing on Apache level, even if Apache runs co-located on the OX nodes and thus cross-routing happens.
There are several reasons why we require session stability in exactly this way. We require session stabilty for horizontal scale-out; while we support transparent resuming / migration of user sessions in the OX cluster without need for users to re-authenticate, sessions wandering around randomly will consume a fixed amount resources corresponding to a running session on each OX node in the cluster, while a session sticky to one OX node will consume this fixed amount of resources only on one OX node. Furthermore there are mechanisms in OX like TokenLogin which work only of all requests beloning to one sequence get routed to the same OX node even if they stem from different machines with different IPs. Only the JSESSIONID (which in this case is transferred as jsessionid path component, as cookies do not work during a 302 redirect, which is part of this sequence) carries the required information where the request must be routed to.
Usual "routing based on cookie hash" is not sufficient here since it disregards the information which machine originally issued the cookie. It only ensures that the session will be sticky to any target, which statistically will not be the same machine that issued the cookie. OX will then set a new JSESSIONID cookie, assuming the session had been migrated. The loadbalancer will then route the session to a different target, as the hash of the cookie will differ. This procedure then happens iteratively until by chance the routing based on cookie hash will route the session to the correct target. By then, a lot of resources will have been wasted, by creating full (short-term) sessions on all OX nodes. Furthermore, processes like TokenLogin will not work this way.
Configuration
All settings regarding cluster setup are located in the configuration file hazelcast.properties. The former used additional files cluster.properties, mdns.properties and static-cluster-discovery.properties are no longer needed. The following gives an overview about the most important settings - please refer to the inline documentation of the configuration file for more advanced options.
Note: The configuration guide targets v7.4.0 of the OX server (and above). For older versions, please consult the history of this page.
General
To restrict access to the cluster and to separate the cluster from others in the local network, a name and password needs to be defined. Only backend nodes having the same values for those properties are able to join and form a cluster.
# Configures the name of the cluster. Only nodes using the same group name
# will join each other and form the cluster. Required if
# "com.openexchange.hazelcast.network.join" is not "empty" (see below).
com.openexchange.hazelcast.group.name=
# The password used when joining the cluster. Defaults to "wtV6$VQk8#+3ds!a".
# Please change this value, and ensure it's equal on all nodes in the cluster.
com.openexchange.hazelcast.group.password=wtV6$VQk8#+3ds!a
Network
It's required to define the network interface that is used for cluster communication via com.openexchange.hazelcast.network.interfaces. By default, the interface is restricted to the local loopback address only. To allow the same configuration amongst all nodes in the cluster, it's recommended to define the value using a wildcard matching the IP addresses of all nodes participating in the cluster, e.g. 192.168.0.*
# Comma-separated list of interface addresses hazelcast should use. Wildcards
# (*) and ranges (-) can be used. Leave blank to listen on all interfaces
# Especially in server environments with multiple network interfaces, it's
# recommended to specify the IP-address of the network interface to bind to
# explicitly. Defaults to "127.0.0.1" (local loopback only), needs to be
# adjusted when building a cluster of multiple backend nodes.
com.openexchange.hazelcast.network.interfaces=127.0.0.1
To form a cluster of multiple OX server nodes, different discovery mechanisms can be used. The discovery mechanism is specified via the property com.openexchange.hazelcast.network.join:
# Specifies which mechanism is used to discover other backend nodes in the
# cluster. Possible values are "empty" (no discovery for single-node setups),
# "static" (fixed set of cluster member nodes) or "multicast" (automatic
# discovery of other nodes via multicast). Defaults to "empty". Depending on
# the specified value, further configuration might be needed, see "Networking"
# section below.
com.openexchange.hazelcast.network.join=empty
Generally, it's advised to use the same network join mechanism for all nodes in the cluster, and, in most cases, it's strongly recommended to use a static network join configuration. This will allow the nodes to join the cluster directly upon startup. With a multicast based setup, nodes will merge to an existing cluster possibly at some later time, thus not being able to access the distributed data until they've joined.
Depending on the network join setting, further configuration may be necessary, as decribed in the following paragraphs.
empty
When using the default value empty, no other nodes are discovered in the cluster. This value is suitable for single-node installations. Note that other nodes that are configured to use other network join mechanisms may be still able to still to connect to this node, e.g. using a static network join, having the IP address of this host in the list of potential cluster members (see below).
static
The most common setting for com.openexchange.hazelcast.network.join is static. A static cluster discovery uses a fixed list of IP addresses of the nodes in the cluster. During startup and after a specific interval, the underlying Hazelcast library probes for not yet joined nodes from this list and adds them to the cluster automatically. The address list is configured via com.openexchange.hazelcast.network.join.static.nodes:
# Configures a comma-separated list of IP addresses / hostnames of possible
# nodes in the cluster, e.g. "10.20.30.12, 10.20.30.13:5701, 192.178.168.110".
# Only used if "com.openexchange.hazelcast.network.join" is set to "static".
# It doesn't hurt if the address of the local host appears in the list, so
# that it's still possible to use the same list throughout all nodes in the
# cluster.
com.openexchange.hazelcast.network.join.static.nodes=
For a fixed set of backend nodes, it's recommended to simply include the IP addresses of all nodes in the list, and use the same configuration for each node. However, it's only required to add the address of at least one other node in the cluster to allow the node to join the cluster. Also, when adding a new node to the cluster and this list is extended accordingly, existing nodes don't need to be shut down to recognize the new node, as long as the new node's address list contains at least one of the already running nodes.
multicast
For highly dynamic setups where nodes are added and removed from the cluster quite often and/or the host's IP addresses are not fixed, it's also possible to configure the network join via multicast. During startup and after a specific interval, the backend nodes initiate the multicast join process automatically, and discovered nodes form or join the cluster afterwards. The multicast group and port can be configured as follows:
# Configures the multicast address used to discover other nodes in the cluster
# dynamically. Only used if "com.openexchange.hazelcast.network.join" is set
# to "multicast". If the nodes reside in different subnets, please ensure that
# multicast is enabled between the subnets. Defaults to "224.2.2.3".
com.openexchange.hazelcast.network.join.multicast.group=224.2.2.3
# Configures the multicast port used to discover other nodes in the cluster
# dynamically. Only used if "com.openexchange.hazelcast.network.join" is set
# to "multicast". Defaults to "54327".
com.openexchange.hazelcast.network.join.multicast.port=54327
Example
The following example shows how a simple cluster named MyCluster consisting of 4 backend nodes can be configured using static cluster discovery. The node's IP addresses are 10.0.0.15, 10.0.0.16, 10.0.0.17 and 10.0.0.18. Note that the same hazelcast.properties is used by all nodes.
com.openexchange.hazelcast.group.name=MyCluster
com.openexchange.hazelcast.group.password=secret
com.openexchange.hazelcast.network.join=static
com.openexchange.hazelcast.network.join.static.nodes=10.0.0.15,10.0.0.16,10.0.0.17,10.0.0.18
com.openexchange.hazelcast.network.interfaces=10.0.0.*
Advanced Configuration
Custom Partitioning (preliminary)
While originally being desgined to separate the nodes holding distributed data into different risk groups for increased fail safety, a custom partioning strategy may also be used to distinguish between nodes holding distributed data from those who should not.
This approach of custom partitioning may be used in a OX cluster, where usually different backend nodes serve different purposes. A common scenario is that there are nodes handling requests from the web interfaces, and others being responsible for USM/EAS traffic. Due to their nature of processing large chunks of synchronization data in memory, the USM/EAS nodes may encounter small delays when the Java garbage collector kicks in and suspends the Java Virtual Machine. Since those delays may also have an influence on hazelcast-based communication in the cluster, the idea is to instruct hazelcast to not store distributed data on that nodes. This is where a custom partitioning scheme comes into play.
To setup a custom paritioning scheme in the cluster, an additional hazelcast.xml configuration file is used, which should be placed into the hazelcast subdirectory of the OX configuration folder, usually at /opt/openexchange/etc/hazelcast. Please note that it's vital that each node in the cluster is configured equally here, so the same hazelcast.xml file should be copied to each server. The configuration read from there is used as basis for all further settings that are taken from the ordinary hazelcast.properties config file.
To setup a custom paritioning scheme, the partition groups must be defined in the hazelcast.xml file. See the following file for an example configuration, where the three nodes 10.10.10.60, 10.10.10.61 and 10.10.10.62 are defined to form an own paritioning group each. Doing so, all distributed data will be stored at one of those nodes physically, while the corresponding backup data (if configured) at one of the other two nodes. All other nodes in the cluster will not be used to store distributed data, but will still be "full" hazelcast members, which is necessary for other cluster-wide operations the OX backends use.
Please note that the configured backup count in the map configurations should be smaller than the number of nodes here, otherwise, there may be problems if one of those data nodes is shut down temporarily for maintenance. So, the minimum number of nodes to define in the partition group sections is implicitly bound to the sum of a map's backupCount and asyncBackupCount properties, plus 1 for the original data partition.
<?xml version="1.0" encoding="UTF-8"?>
<hazelcast xsi:schemaLocation="http://www.hazelcast.com/schema/config hazelcast-config-3.1.xsd"
xmlns="http://www.hazelcast.com/schema/config"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<partition-group enabled="true" group-type="CUSTOM">
<member-group>
<interface>10.10.10.60</interface>
</member-group>
<member-group>
<interface>10.10.10.61</interface>
</member-group>
<member-group>
<interface>10.10.10.62</interface>
</member-group>
</partition-group>
</hazelcast>
More general information regarding custom partioning is available at http://hazelcast.org/docs/latest/manual/html/partitiongroupconfig.html .
It's also recommended to use a "static" cluster discovery for the network join, and list same the nodes that are also configured in the parition groups here, so that join requests are handled by those nodes, too (and not the other nodes that are potentially prone to garbage collection delays.
After configuring a custom paritioning scheme, the data distribution may be verified, e.g. by inspecting the MBeans of the distributed maps via JMX.
Features
The following list gives an overview about different features that were implemented using the new cluster capabilities.
Distributed Session Storage
Previously, when an Open-Xchange server was shutdown for maintenance, all user sessions that were bound to that machine were lost, i.e. the users needed to login again. With the distributed session storage, all sessions are backed by a distributed map in the cluster, so that they are no longer bound to a specific node in the cluster. When a node is shut down, the session data is still available in the cluster and can be accessed from the remaining nodes. The load-balancing techniques of the webserver then seamlessly routes the user session to another node, with no session expired errors. The distributed session storage comes with the package open-xchange-sessionstorage-hazelcast. It's recommended to install this optional package in all clustered environments with multiple groupware server nodes.
Note: While there's some kind of built-in session distribution among the nodes in the cluster, this should not be seen as a replacement for session-stickiness between the loadbalancer and groupware nodes, i.e. one should still configure the webserver to use sticky sessions for performance reasons.
Depending on the cluster infrastructure, different backup-count configuration options might be set for the distributed session storage in the map configuration file sessions.properties in the hazelcast subdirectory:
com.openexchange.hazelcast.configuration.map.backupCount=1
The backupcount property configures the number of nodes with synchronized backups. Synchronized backups block operations until backups are successfully copied and acknowledgements are received. If 1 is set as the backup-count for example, then all entries of the map will be copied to another JVM for fail-safety. 0 means no backup. Any integer between 0 and 6. Default is 1, setting bigger than 6 has no effect.
com.openexchange.hazelcast.configuration.map.asyncBackupCount=0
The asyncbackup property configures the number of nodes with async backups. Async backups do not block operations and do not require acknowledgements. 0 means no backup. Any integer between 0 and 6. Default is 0, setting bigger than 6 has no effect.
Since session data is backed up by default continously by multiple nodes in the cluster, the steps described in Session_Migration to trigger session mirgration to other nodes explicitly is obsolete and no longer needed with the distributed session storage.
Normally, sessions in the distributed storages are not evicted automatically, but are only removed when they're also removed from the session handler, either due to a logout operation or when exceeding the long-term session lifetime as configured by com.openexchange.sessiond.sessionLongLifeTime in sessiond.properties. Under certain circumstances, i.e. the session is no longer accessed by the client and the OX node hosting the session in it's long-life container being shutdown, the remove operation from the distributed storage might not be triggered. Therefore, additionaly a maximum idle time of map-entries can be configured for the distributed sessions map via
com.openexchange.hazelcast.configuration.map.maxIdleSeconds=640000
To avoid unnecessary eviction, the value should be higher than the configured com.openexchange.sessiond.sessionLongLifeTime in sessiond.properties.
Distributed Indexing Jobs
Groupware data is indexed in the background to yield faster search results. See the article on the Indexing Bundle for more.
Remote Cache Invalidation
For faster access, groupware data is held in different caches by the server. Formerly, the caches utilized the TCP Lateral Auxiliary Cache plug in (LTCP) for the underlying JCS caches to broadcast updates and removals to caches on other OX nodes in the cluster. This could potentially lead to problems when remote invalidation was not working reliably due to network discovery problems. As an alternative, remote cache invalidation can also be performed using reliable publish/subscribe events built up on Hazelcast topics. This can be configured in the cache.properties configuration file, where the 'eventInvalidation' property can either be set to 'false' for the legacy behavior or 'true' for the new mechanism:
com.openexchange.caching.jcs.eventInvalidation=true
All nodes participating in the cluster should be configured equally.
Internally, if com.openexchange.caching.jcs.eventInvalidation is set to true, LTCP is disabled in JCS caches. Instead, an internal mechanism based on distributed Hazelcast event topics is used to invalidate data throughout all nodes in the cluster after local update- and remove-operations. Put-operations aren't propagated (and haven't been with LTCP either), since all data put into caches can be locally loaded/evaluated at each node from the persistent storage layer.
Using Hazelcast-based cache invalidation also makes further configuration of the JCS auxiliaries obsolete in the cache.ccf configuration file. In that case, all jcs.auxiliary.LTCP.* configuration settings are virtually ignored. However, it's still required to mark caches that require cluster-wide invalidation via jcs.region.<cache_name>=LTCP, just as before. So basically, when using the new default setting com.openexchange.caching.jcs.eventInvalidation=true, it's recommended to just use the stock cache.ccf file, since no further LTCP configuration is required.
Adminstration / Troubleshooting
Hazelcast Configuration
The underlying Hazelcast library can be configured using the file hazelcast.properties.
Important:
By default property com.openexchange.hazelcast.network.interfaces is set to 127.0.0.1; meaning Hazelcast listens only to loop-back device. To build a cluster among remote nodes the appropriate network interface needs to be configured there. Leaving that property empty lets Hazelcast listen to all available network interfaces.
The Hazelcast JMX MBean can be enabled or disabled with the property com.openexchange.hazelcast.jmx. The properties com.openexchange.hazelcast.mergeFirstRunDelay and com.openexchange.hazelcast.mergeRunDelay control the run intervals of the so-called Split Brain Handler of Hazelcast that initiates the cluster join process when a new node is started. More details can be found at http://www.hazelcast.com/docs/2.5/manual/single_html/#NetworkPartitioning.
The port ranges used by Hazelcast for incoming and outgoing connections can be controlled via the configuration parameters com.openexchange.hazelcast.networkConfig.port, com.openexchange.hazelcast.networkConfig.portAutoIncrement and com.openexchange.hazelcast.networkConfig.outboundPortDefinitions.
Commandline Tool
To print out statistics about the cluster and the distributed data, the showruntimestats commandline tool can be executed witht the clusterstats ('c') argument. This provides an overview about the runtime cluster configuration of the node, other members in the cluster and distributed data structures.
JMX
In the Open-Xchange server Java process, the MBean com.hazelcast can be used to monitor and manage different aspects of the underlying Hazelcast cluster. The com.hazelcast MBean provides detailed information about the cluster configuration and distributed data structures.
Hazelcast Errors
When experiencing hazelcast related errors in the logfiles, most likely different versions of the packages are installed, leading to different message formats that can't be understood by nodes using another version. Examples for such errors are exceptions in hazelcast components regarding (de)serialization or other message processing.
This may happen when performing a consecutive update of all nodes in the cluster, where temporarily nodes with a heterogeneous setup try to communicate with each other. If the errors don't disappear after all nodes in the cluster have been update to the same package versions, it might be necessary to shutdown the cluster completely, so that all distributed data is cleared.
Cluster Discovery Errors
- If the started OX nodes don't form a cluster, please double-check your configuration in hazelcast.properties
- It's important to have the same cluster name defined in hazelcast.properties throughout all nodes in the cluster
- Especially when using multicast cluster discovery, it might take some time until the cluster is formed
- When using static cluster discovery, at least one other node in the cluster has to be configured in com.openexchange.hazelcast.network.join.static.nodes to allow joining, however, it's recommended to list all nodes in the cluster here
Disable Cluster Features
The Hazelcast based clustering features can be disabled with the following property changes:
- Disable cluster discovery by setting com.openexchange.hazelcast.network.join to empty in hazelcast.properties
- Disable Hazelcast by setting com.openexchange.hazelcast.enabled to false in hazelcast.properties
- Disable message based cache event invalidation by setting com.openexchange.caching.jcs.eventInvalidation to false in cache.properties
Update from 6.22.1 to version 6.22.2 and above
As hazelcast will be used by default for the distribution of sessions starting 6.22.2 you have to adjust hazelcast according to our old cache configuration. First of all it's important that you install the open-xchange-sessionstorage-hazelcast package. This package will add the binding between hazelcast and the internal session management. Next you have to set a cluster name to the cluster.properties file (see #Cluster Discovery Errors). Furthermore you will have to add one of the two discovery modes mentioned in #Cluster Discovery.
Updating a Cluster
Running a cluster means built-in failover on the one hand, but might require some attention when it comes to the point of upgrading the services on all nodes in the cluster. This chapter gives an overview about general concepts and hints for silent updates of the cluster.
Limitations
While in most cases a seamless, rolling upgrade of all nodes in the cluster is possible, there may be situations where nodes running a newer version of the Open-Xchange Server are not able to communicate with older nodes in the cluster, i.e. can't access distributed data or consume incompatible event notifications - especially, when the underlying Hazelcast library is part of the update, which does not support this scenario at the moment. In such cases, the release notes will contain corresponding information, so please have a look there before applying an update.
Additionally, there may always be some kind of race conditions during an update, i.e. client requests that can't be completed successfully or internal events not being deliverd to all nodes in the cluster. That's why the following information should only serve as a best-practices guide to minimize the impact of upgrades to the user experience.
Upgrading a single Node
Upgrading all nodes in the cluster should usually be done sequentially, i.o.w. one node after the other. This means that during the upgrade of one node, the node is temporarily disconnected from the other nodes in the cluster, and will join the cluster again after the update is completed. From the backend perspective, this is as easy as stopping the open-xchange service. other nodes in the cluster will recognize the disconnected node and start to repartition the shared cluster data automatically. But wait a minute - doing so would potentially lead to the webserver not registering the node being stopped immediately, resulting in temporary errors for currently logged in users until they are routed to another machine in the cluster. That's why it's good practice to tell the webserver's load balancer that the node should no longer fulfill incoming requests. The Apache Balancer Manager is an excellent tool for this (module mod_status). Look at the screen shot. Every node can be put into a disabled mode. Further requests will the redirected to other nodes in the cluster:
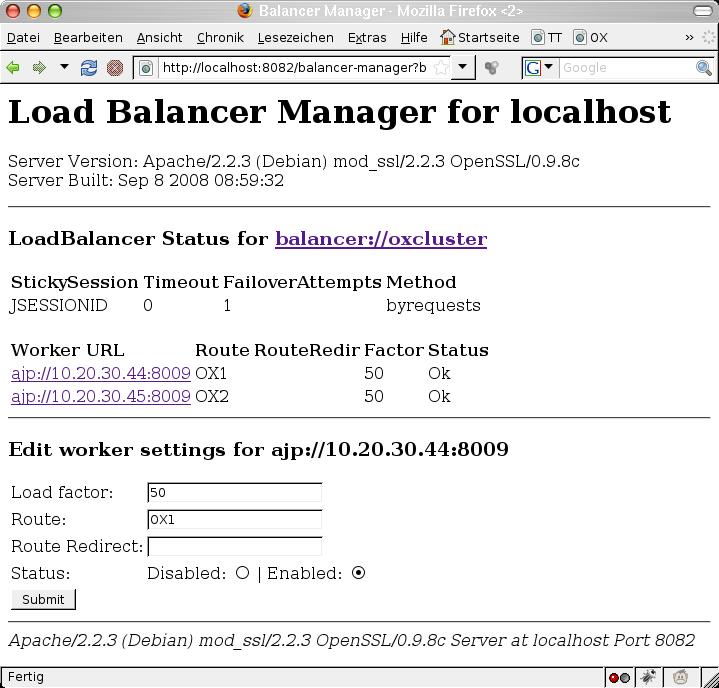
Afterwards, the open-xchange service on the disabled node can be stopped by executing:
$ /etc/init.d/open-xchange stop
or
$ service open-xchange stop
Now, the node is effectively in maintenance mode and any updates can take place. One could now verify the changed cluster infrastructure by accessing the Hazelcast MBeans either via JMX or the showruntimestats -c commandline tool (see above for details). There, the shut down node should no longer appear in the 'Member' section (com.hazelcast:type=Member).
When all upgrades are processed, the node open-xchange service can be started again by executing:
$ /etc/init.d/open-xchange start
or
$ service open-xchange start
As stated above, depending on the chosen cluster discovery mechanism, it might take some time until the node joins the cluster again. When using static cluster discovery, it will join the existing cluster usually directly during serivce startup, i.o.w. before other depending OSGi services are started. Otherwise, there might also be situations where the node cannot join the cluster directly, for example when there were no mDNS advertisments for other nodes in the cluster received yet. Then, it can take some additional time until the node finally joins the cluster. During startup of the node, you can observe the JMX console or the output of showruntimestats -c (com.hazelcast:type=Member) of another node in the cluster to verify when the node has joined.
After the node has joined, distributed data is re-partioned automatically, and the node is ready to server incoming requests again - so now the node can finally be enabled again in the load balancer configuration of the webserver. Afterwards, the next node in the cluster can be upgraded using the same procedure, until all nodes were processed.
Other Considerations
- It's always recommended to only upgrade one node after the other, always ensuring that the cluster has formed correctly between each shutdown/startup of a node.
- Do not stop a node while running the runUpdate script or the associated update task.
- During the time of such a rolling upgrade of all nodes, we have effectively heterogeneous software versions in the cluster, which potentially might lead to temporary inconsistencies. Therefore, all nodes in the cluster should be updated in one cycle (but still one after the other).
- Following the above guideline, it's also possible to add or remove nodes dynamically to the cluster, not only when disconnecting a node temporary for updates.
- In case of trouble, i.e. a node refuses to join the cluster again after restart, consult the logfiles first for any hints about what is causing the problem - both on the disconnected node, and also on other nodes in the network
- If there are general incompatibilities between two revisions of the Open-Xchange Server that prevent an operation in a cluster (release notes), it's recommended to choose another name for the cluster in cluster.properties for the nodes with the new version. This will temporary lead to two separate clusters during the rolling upgrade, and finally the old cluster being shut down completely after the last node was updated to the new version. While distributed data can't be migrated from one server version to another in this scenario due to incompatibilities, the uptime of the system itself is not affected, since the nodes in the new cluster are able to serve new incoming requests directly.
